









新闻中心 
【论文复现】 MnasNet复现以及一些感想
 2025-07-31
2025-07-31 浏览次数:次
浏览次数:次 返回列表
返回列表本文围绕MnasNet复现展开,介绍了这一谷歌提出的轻量化网络,其通过自动搜索平衡精度与延迟,采用真实手机环境测延迟。复现基于PyTorch实现转为Paddle版本,调整了因硬件限制的参数,采用预热策略等,还提及训练中遇到的精度提升问题及解决办法,最后分享了复现收获。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【论文复现】 MnasNet复现以及一些感想
简介
概述
MnasNet( mobile neural architecture search),是谷歌提出的一个轻量化网络。
卷积神经网络一直对于移动设备是个挑战,移动端模型一般要求模型小而快,同时对精度也有要求。尽管CNN模型在移动端做了各种改进提升,但是当考虑到许多架构的可能性时,很难手动平衡这些权衡。自动移动神经架构搜索 (MNAS)方法,它明确地将模型延迟纳入主要目标,以便搜索能够识别一个在准确性和延迟之间实现良好权衡的模型。
与之前的方法预估延迟不同的是,他们直接采用真实环境中手机上的模型预测延时,之前方法通常是采用不精确的模式(如:FLOPS)。为了进一步在灵活性和搜索空间大小之间取得适当的平衡,作者提出了一种新的分解层次搜索空间,它鼓励整个网络中的层多样性。实验结果表明,他们的方法始终优于当时最先进的移动端的CNN跨多个视觉任务的模型。在ImageNet分类任务中取得精确度为75.2%的top1,在手机端的延时为78ms,速度是mobileNetV2的1.8倍,同时精确度比其高0.5%。
Mnasnet网络是介于mobilenetV2和mobilenetV3之间的一个网络,这个网络是采用强化学习搜索出来的一个网络,具体模式如下:
实验方法:
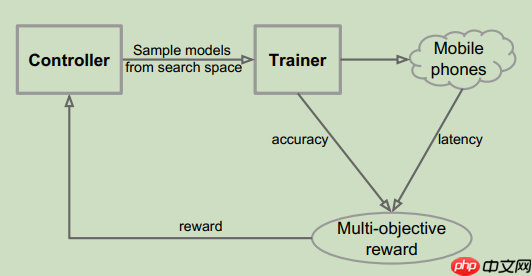
像在ImageNet或COCO这样的大型任务上直接搜索CNN模型是昂贵的,因为每个模型需要几天才能收敛。虽然以前的方法主要对较小的任务(如CIFAR-10)执行模型搜索。在本文中,作者直接在ImageNet训练集上执行模型搜索,但训练步骤较少(5epoch)。通常,从训练集中随机选择50K图像作为固定验证集。为了确保精度的提高来自于搜索空间,使用了与NASNet相同的RNN控制器,尽管它效率不高:
在64台TPUv2设备上,每个模型搜索需要4.5天。在训练过程中,通过在Pixel 1手机的单线程大CPU内核上运行来测量每个采样模型的真实延迟。总的来说,大约采样了8K个模型,但是只有15个性能最好的型号被传输到完整的ImageNet,只有1个模型可以迁移到到COCO数据集上使用。
模型结构

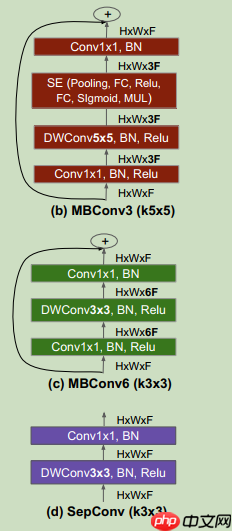
与之前的其他模型不同的是,此模型使用了3X3和5X5的卷积,这和之前其他网络不同点。左图为模型的主结构,右图为模型的子模块具体指代。
实现
mnasnet的实现基于pytorch的实现 由于paddlepaddle和pytorch的接口实现基本用法差别不大,所以在复现中实现的速度要快很多,但是同时也引入了新的问题,我们会一一说明。 pytorch的实现在关键点上的超参数以及具体实现基本已经给出。我们做的主要是实现Paddle版本的模型。
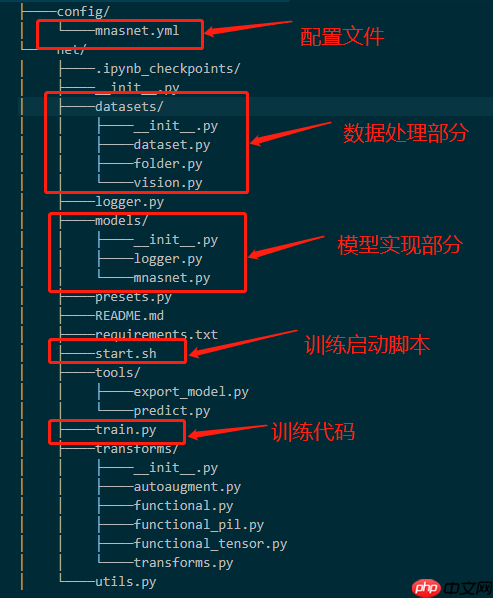
代码的具体实现在路径:work/PP-Mnasnet/net/models/mnasnet.py下面,大家有问题的可以细看。代码结构如下

参数及方法设置
论文中关于优化器以及超参数学习率等参数,论文中都已经给出,但是实际的由于训练使用的硬件差异,我们不可能按照论文中的参数直接拿来使用。
先列举论文中用到的一些方法及参数:
 SCA介绍及应用实例 中文WORD版
SCA介绍及应用实例 中文WORD版
本文档主要讲述的是SCA介绍及应用实例;SCA(Service Component Architecture)是针对SOA提出的一套服务体系构建框架协议,内部既融合了IOC的思想,同时又把面向对象的复用由代码复用上升到了业务模块组件复用,同时将服务接口,实现,部署,调用完全分离,通过配置的形式灵活的组装,绑定。希望本文档会给有需要的朋友带来帮助;感兴趣的朋友可以过来看看
 0
查看详情
0
查看详情


- input_size: 224 X 224
- bach_size: 4K
- warm_up: True / 5 epoch
- lr_scheduler: RMSProp
- lr:0.256
- dropout:0.2
- momentum:0.9
单看batch_size的大小4K,这就不是一般硬件能够达到的要求(据说这个模型在搜索出来的时候,资金花费是100K$),所以Batch_size根据实际情况来进行设定;
相对应的lr我们也应该进行调整,不宜设置为论文中的那样,基础的从0.001开始就行。如果最初的lr设置过大,基本在进行几十个epoch后,acc和其他参数指标基本没有大的变化,类似如下:
top1: 0.00090, top5: 0.00473, lr: 0.20480, loss: 7.93936, *g_reader_cost: 0.04303 sec, *g_batch_cost: 0.10214 sec, *g_samples: 64.0, *g_ips: 626.62028 top1: 0.00105, top5: 0.00488, lr: 0.20480, loss: 7.69394, *g_reader_cost: 0.04656 sec, *g_batch_cost: 0.10620 sec, *g_samples: 64.0, *g_ips: 602.63657 top1: 0.00094, top5: 0.00434, lr: 0.20480, loss: 8.00038, *g_reader_cost: 0.04546 sec, *g_batch_cost: 0.10643 sec, *g_samples: 64.0, *g_ips: 601.34891 top1: 0.00086, top5: 0.00512, lr: 0.20480, loss: 7.47677, *g_reader_cost: 0.04140 sec, *g_batch_cost: 0.10397 sec, *g_samples: 64.0, *g_ips: 615.57468 top1: 0.00125, top5: 0.00508, lr: 0.20480, loss: 7.45593, *g_reader_cost: 0.04609 sec, *g_batch_cost: 0.10522 sec, *g_samples: 64.0, *g_ips: 608.27140 top1: 0.00086, top5: 0.00527, lr: 0.20480, loss: 7.76873, *g_reader_cost: 0.04692 sec, *g_batch_cost: 0.10712 sec, *g_samples: 64.0, *g_ips: 597.46578 top1: 0.00078, top5: 0.00453, lr: 0.20480, loss: 7.49132, *g_reader_cost: 0.04431 sec, *g_batch_cost: 0.10443 sec, *g_samples: 64.0, *g_ips: 612.87012 top1: 0.00074, top5: 0.00492, lr: 0.20480, loss: 7.57973, *g_reader_cost: 0.05430 sec, *g_batch_cost: 0.11359 sec, *g_samples: 64.0, *g_ips: 563.42090 top1: 0.00086, top5: 0.00508, lr: 0.20480, loss: 7.92624, *g_reader_cost: 0.04599 sec, *g_batch_cost: 0.10737 sec, *g_samples: 64.0, *g_ips: 596.08218 top1: 0.00102, top5: 0.00465, lr: 0.20480, loss: 8.07673, *g_reader_cost: 0.05052 sec, *g_batch_cost: 0.10950 sec, *g_samples: 64.0, *g_ips: 584.49763
warmup是较好的提分策略,并且能够在实际过程中加快模型拟合。由于训练的数据集使用的是ImageNet,分类为1000,完整的数据集大概144G,如果用aistudio我们也需要训练很久。
在确定了上述的方法策略后,最初的训练集在官方提供的数据集大概66G上直接进行训练。但是实际的训练在经过一天后,实际的acc增长还是比较低。当时采用了新的策略:在miniImageNet上进行训练,大概12个小时候就拟合了。我们将此模型在官方提供的数据集上进行训练,开始的acc可以达到0.22左右。这要比实际的直接进行训练速度要快很多。
训练代码的实现在:work/PP-Mnasnet/net/train.py这个目录下。这样在训练了大概三天后,我们的模型acc精度可以达到0.65左右:
[2025/12/30 13:07:21] root INFO: [Epoch 91, iter: 16400] top1: 0.63598, top5: 0.83176, lr: 0.00120, loss: 1.79083, *g_reader_cost: 0.05147 sec, *g_batch_cost: 0.10281 sec, *g_samples: 64.0, *g_ips: 622.48323 images/sec.[2025/12/30 13:08:16] root INFO: [Epoch 91, iter: 16800] top1: 0.63836, top5: 0.83211, lr: 0.00120, loss: 1.45224, *g_reader_cost: 0.04990 sec, *g_batch_cost: 0.10145 sec, *g_samples: 64.0, *g_ips: 630.85575 images/sec.[2025/12/30 13:09:10] root INFO: [Epoch 91, iter: 17200] top1: 0.63187, top5: 0.83004, lr: 0.00120, loss: 1.95962, *g_reader_cost: 0.04719 sec, *g_batch_cost: 0.09977 sec, *g_samples: 64.0, *g_ips: 641.49160 images/sec.[2025/12/30 13:10:05] root INFO: [Epoch 91, iter: 17600] top1: 0.63000, top5: 0.83313, lr: 0.00120, loss: 1.98715, *g_reader_cost: 0.05027 sec, *g_batch_cost: 0.10245 sec, *g_samples: 64.0, *g_ips: 624.67859 images/sec.[2025/12/30 13:10:59] root INFO: [Epoch 91, iter: 18000] top1: 0.62883, top5: 0.82902, lr: 0.00120, loss: 1.93626, *g_reader_cost: 0.04727 sec, *g_batch_cost: 0.10032 sec, *g_samples: 64.0, *g_ips: 637.96714 images/sec.[2025/12/30 13:11:53] root INFO: [Epoch 91, iter: 18400] top1: 0.62855, top5: 0.82527, lr: 0.00120, loss: 1.35887, *g_reader_cost: 0.04998 sec, *g_batch_cost: 0.10153 sec, *g_samples: 64.0, *g_ips: 630.35848 images/sec.[2025/12/30 13:12:49] root INFO: [Epoch 91, iter: 18800] top1: 0.62773, top5: 0.82719, lr: 0.00120, loss: 1.83990, *g_reader_cost: 0.05086 sec, *g_batch_cost: 0.10312 sec, *g_samples: 64.0, *g_ips: 620.65365 images/sec.[2025/12/30 13:13:43] root INFO: [Epoch 91, iter: 19200] top1: 0.63160, top5: 0.82840, lr: 0.00120, loss: 1.59238, *g_reader_cost: 0.04715 sec, *g_batch_cost: 0.10000 sec, *g_samples: 64.0, *g_ips: 639.99664 images/sec.[2025/12/30 13:14:38] root INFO: [Epoch 91, iter: 19600] top1: 0.63152, top5: 0.83004, lr: 0.00120, loss: 1.68316, *g_reader_cost: 0.05057 sec, *g_batch_cost: 0.10349 sec, *g_samples: 64.0, *g_ips: 618.40716 images/sec.[2025/12/30 13:15:31] root INFO: [Epoch 91, iter: 20000] top1: 0.63129, top5: 0.82945, lr: 0.00120, loss: 1.62996, *g_reader_cost: 0.04641 sec, *g_batch_cost: 0.09755 sec, *g_samples: 64.0, *g_ips: 656.05389 images/sec.[2025/12/30 13:15:34] root INFO: The best model is in epoch [91] and the acc1 is [0.6335090398788452]
论文复现流程:
官方在论文复现方面有个很好的流程,具体可参考
在复现中如果出现精度等其他问题,可以参考官方推荐的流程进行核对对齐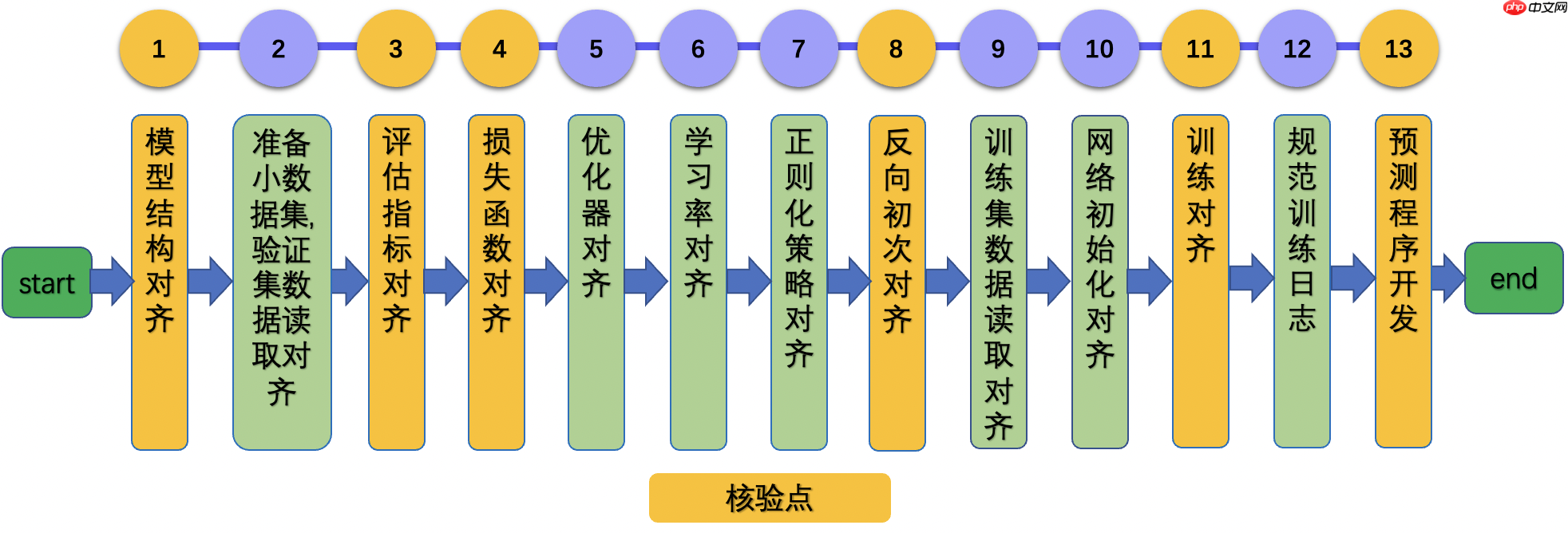
出现的问题(目前已初步知晓):
在acc达到0.65后就没有继续提升,论文中以及Pythorch实现的acc top1可以达到0.735。 在复现中断了一段时间后,关注到有人在组网的网络可分离卷积网络最后中加入relu(在模型实现代码中work/PP-Mnasnet/net/models/mnasnet.py的第129行添加这个激活层)后继续训练,acc基本接近论文的精度。
参考了paddle模型库中关于可分离卷积的写法,最后一步基本都有激活函数,对于轻量级的网络可能用relu/relu6或者hardswish函数实现。关于这两者的差异,目前还不太清楚原因。有明白的大佬希望在评论区留言解惑。
这也许是这次复现的一个很大的收获,关注具体模块的实现方法,平时需要加强源码阅读以及自己多思考问题能力。
以上就是【论文复现】 MnasNet复现以及一些感想的详细内容,更多请关注其它相关文章!
# ai
# 淄博网站建设心得
# 长沙哪里优化网站
# 公司网站建设的特点包括
# 铜梁区网站建设哪家好点
# 乐园推广营销案例分析题
# 营销推广计划书
# 福田平台网站优化公司
# 大白兔奶糖营销主题推广
# 过程中
# 要快
# 图为
# 多项
# 复用
# 接棒
# 可以达到
# 应用实例
# 的是
# 中文网
# coco
# udio
# cos
# 谷歌
# 区域seo推广哪家便宜
# 网站建设优化运营策略研究
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何打开命令提示符
市盈率底下 18A 19E 是什么意思
学typescript需要多久
咋免费领取爱奇艺会员 如何免费领取爱奇艺会员步骤
如何把u盘改成固态硬盘
.asm如何在命令行运行
单片机怎么控制闪烁技术
typescript要用什么工具
win7旗舰版wifi怎么打开
固态硬盘如何装入机箱
typescript怎么拼接
照相机上面power是什么意思
记录仪power灯亮是什么意思
如何在昇腾Ascend 910B上运行Qwen2.5教程
春运订票什么时候抢票
喇叭上标的power30w是什么意思
j*a数组怎么比较abc
怎么关360壁纸广告
春运大巴上抢票怎么抢票
市盈率市净率是什么意思
如何加装固态硬盘
docs命令如何进入d
夸克文字口令是什么意思
固态硬盘内存如何查找
如何检测固态硬盘温度
春运抢票可以抢几张
如何修改域名解析
为什么都做折叠屏手机呢
typescript多久能学会
如何4k对齐固态硬盘
faq是什么意思
夸克用的什么服务器
移动固态硬盘如何使用
如何学习typescript
如何更新typescript
43寸电视长宽多少厘米
a03怎么根据编号找文链接入口
笔记本如何使用固态硬盘
摄像机的power chg是什么意思中文
typescript接口怎么选
vue中datediff函数怎么用
三星相机里power是什么意思
市盈率为负数是什么意思
春运抢票多久能知道成功
vs怎么编写typescript
哪些编程软件需用typescript
linux命令行如何使用中文输入法
单片机学习视频怎么调色
新买的固态硬盘如何查
路由器上面的power红灯是什么意思
