









新闻中心 
【第五期论文复现赛-语义分割】ENCNet
 2025-07-17
2025-07-17 浏览次数:次
浏览次数:次 返回列表
返回列表本文作者引入了上下文编码模块(Context Encoding Module),在语义分割任务中利用全局上下文信息来提升语义分割的效果。本次复现赛要求是在Cityscapes验证集上miou为78.55%,本次复现的miou为79.42%,该算法已被PaddleSeg收录。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【论文复现赛】ENCNet:Context Encoding for Semantic Segmentation
本文作者引入了上下文编码模块(Context Encoding Module),在语义分割任务中利用全局上下文信息来提升语义分割的效果。本次复现赛要求是在Cityscapes验证集上miou为78.55%,本次复现的miou为79.42%,该算法已被PaddleSeg收录。一、引言
PSPNet通过SPP(Spatial Pyramid polling)模块得到不同尺寸的特征图,然后将不同尺寸的特征图结合扩大感受野;DeepLab利用ASPP(Atrous Spatial Pyramid Pooling)来扩大感受野。但是ENCNet提出了一个问题:“Is capturing contextual information the same as increasing the receptive field size?”(增加感受野等于捕获上下文信息吗?)。作者提出一个想法:利用图片的上下文信息来减少图片中像素种类的搜索空间。比如一张卧室的图片,那么该图片中有床、椅子等物体的可能性就会比汽车、湖面等其他物体的概率大很多。本文提出了Context Encoding Module和Semantic Encoding Loss(SE-loss)来学习上下文信息。
二、网络结构
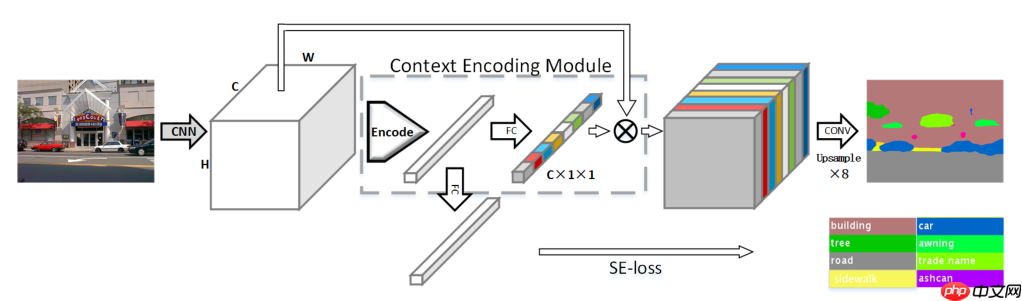 上图为ENCNet的网络结构,主要包括Context Encoding Module, Featuremap Attention和Semantic Encoding Loss。
上图为ENCNet的网络结构,主要包括Context Encoding Module, Featuremap Attention和Semantic Encoding Loss。
Context Encoding Module:该模块对输入的特征图进行编码得到编码后的语义向量(原文中叫做encoded semantics),得到的语义向量有2个用处,第一个是送入Featuremap Attention用作注意力机制的权重,另一个用处是用于计算Semantic Encoding Loss。
Featuremap Attention:该模块使得模型更注重于信息量大的channel特征,抑制不重要的channel特征。例如在一张背景为天空的图片中,存在飞机的可能性就会比汽车的可能性大。
Semantic Encoding Loss:像素级的交叉熵损失函数无法考虑到全局信息,可能会导致小目标无法正常识别,而SELoss可以平等的考虑不同大小的目标。SELoss损失的target是一个(N, NUM_CLASSES)的矩阵,它的构造也很简单,如果图片中存在某种物体,则对应的target的标签就为1。
三、实验结果

上图为ENCNet在ADE20K数据集的预测结果,与FCN对比,可以看出ENCNet利用全局语义信息的显著优点:
1、第一行图片中,FCN将sand分类成了earth,ENCNet利用了全局信息(海边大概率存在沙)正确分类;
2、第二、四行图片中,FCN很难区分building,house和skyscraper这3类;
3、第三行,FCN将 windowpane分类成door。
 美图云修
美图云修
商业级AI影像处理工具
 50
查看详情
50
查看详情

四、核心代码
class Encoding(nn.Layer):
def __init__(self, channels, num_codes):
super().__init__()
 self.channels, self.num_codes = channels, num_codes
std = 1 / ((channels * num_codes) ** 0.5)
self.codewords = self.create_parameter(
shape=(num_codes, channels),
default_initializer=nn.initializer.Uniform(-std, std),
) # 编码
self.scale = self.create_parameter(
shape=(num_codes,),
default_initializer=nn.initializer.Uniform(-1, 0),
) # 缩放因子
self.channels = channels def scaled_l2(self, x, codewords, scale):
num_codes, channels = paddle.shape(codewords)
reshaped_scale = scale.reshape([1, 1, num_codes])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
scaled_l2_norm = paddle.multiply(reshaped_scale, (expanded_x - reshaped_codewords).pow(2).sum(axis=3)) return scaled_l2_norm def aggregate(self, assignment_weights, x, codewords):
num_codes, channels = paddle.shape(codewords)
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
encoded_feat = paddle.multiply(assignment_weights.unsqueeze(3), (expanded_x - reshaped_codewords)).sum(axis=1)
encoded_feat = paddle.reshape(encoded_feat, [-1, self.num_codes, self.channels]) return encoded_feat
def forward(self, x):
x_dims = x.ndim assert x_dims == 4, "The dimension of input tensor must equal 4, but got {}.".format(x_dims) assert paddle.shape(x)[1] == self.channels, "Encoding channels error, excepted {} but got {}.".format(self.channels, paddle.shape(x)[1])
batch_size = paddle.shape(x)[0]
x = x.reshape([batch_size, self.channels, -1]).transpose([0, 2, 1])
assignment_weights = F.softmax(self.scaled_l2(x, self.codewords, self.scale), axis=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords) return encoded_feat
self.channels, self.num_codes = channels, num_codes
std = 1 / ((channels * num_codes) ** 0.5)
self.codewords = self.create_parameter(
shape=(num_codes, channels),
default_initializer=nn.initializer.Uniform(-std, std),
) # 编码
self.scale = self.create_parameter(
shape=(num_codes,),
default_initializer=nn.initializer.Uniform(-1, 0),
) # 缩放因子
self.channels = channels def scaled_l2(self, x, codewords, scale):
num_codes, channels = paddle.shape(codewords)
reshaped_scale = scale.reshape([1, 1, num_codes])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
scaled_l2_norm = paddle.multiply(reshaped_scale, (expanded_x - reshaped_codewords).pow(2).sum(axis=3)) return scaled_l2_norm def aggregate(self, assignment_weights, x, codewords):
num_codes, channels = paddle.shape(codewords)
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
encoded_feat = paddle.multiply(assignment_weights.unsqueeze(3), (expanded_x - reshaped_codewords)).sum(axis=1)
encoded_feat = paddle.reshape(encoded_feat, [-1, self.num_codes, self.channels]) return encoded_feat
def forward(self, x):
x_dims = x.ndim assert x_dims == 4, "The dimension of input tensor must equal 4, but got {}.".format(x_dims) assert paddle.shape(x)[1] == self.channels, "Encoding channels error, excepted {} but got {}.".format(self.channels, paddle.shape(x)[1])
batch_size = paddle.shape(x)[0]
x = x.reshape([batch_size, self.channels, -1]).transpose([0, 2, 1])
assignment_weights = F.softmax(self.scaled_l2(x, self.codewords, self.scale), axis=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords) return encoded_feat
 self.channels, self.num_codes = channels, num_codes
std = 1 / ((channels * num_codes) ** 0.5)
self.codewords = self.create_parameter(
shape=(num_codes, channels),
default_initializer=nn.initializer.Uniform(-std, std),
) # 编码
self.scale = self.create_parameter(
shape=(num_codes,),
default_initializer=nn.initializer.Uniform(-1, 0),
) # 缩放因子
self.channels = channels def scaled_l2(self, x, codewords, scale):
num_codes, channels = paddle.shape(codewords)
reshaped_scale = scale.reshape([1, 1, num_codes])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
scaled_l2_norm = paddle.multiply(reshaped_scale, (expanded_x - reshaped_codewords).pow(2).sum(axis=3)) return scaled_l2_norm def aggregate(self, assignment_weights, x, codewords):
num_codes, channels = paddle.shape(codewords)
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
encoded_feat = paddle.multiply(assignment_weights.unsqueeze(3), (expanded_x - reshaped_codewords)).sum(axis=1)
encoded_feat = paddle.reshape(encoded_feat, [-1, self.num_codes, self.channels]) return encoded_feat
def forward(self, x):
x_dims = x.ndim assert x_dims == 4, "The dimension of input tensor must equal 4, but got {}.".format(x_dims) assert paddle.shape(x)[1] == self.channels, "Encoding channels error, excepted {} but got {}.".format(self.channels, paddle.shape(x)[1])
batch_size = paddle.shape(x)[0]
x = x.reshape([batch_size, self.channels, -1]).transpose([0, 2, 1])
assignment_weights = F.softmax(self.scaled_l2(x, self.codewords, self.scale), axis=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords) return encoded_feat
self.channels, self.num_codes = channels, num_codes
std = 1 / ((channels * num_codes) ** 0.5)
self.codewords = self.create_parameter(
shape=(num_codes, channels),
default_initializer=nn.initializer.Uniform(-std, std),
) # 编码
self.scale = self.create_parameter(
shape=(num_codes,),
default_initializer=nn.initializer.Uniform(-1, 0),
) # 缩放因子
self.channels = channels def scaled_l2(self, x, codewords, scale):
num_codes, channels = paddle.shape(codewords)
reshaped_scale = scale.reshape([1, 1, num_codes])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
scaled_l2_norm = paddle.multiply(reshaped_scale, (expanded_x - reshaped_codewords).pow(2).sum(axis=3)) return scaled_l2_norm def aggregate(self, assignment_weights, x, codewords):
num_codes, channels = paddle.shape(codewords)
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
encoded_feat = paddle.multiply(assignment_weights.unsqueeze(3), (expanded_x - reshaped_codewords)).sum(axis=1)
encoded_feat = paddle.reshape(encoded_feat, [-1, self.num_codes, self.channels]) return encoded_feat
def forward(self, x):
x_dims = x.ndim assert x_dims == 4, "The dimension of input tensor must equal 4, but got {}.".format(x_dims) assert paddle.shape(x)[1] == self.channels, "Encoding channels error, excepted {} but got {}.".format(self.channels, paddle.shape(x)[1])
batch_size = paddle.shape(x)[0]
x = x.reshape([batch_size, self.channels, -1]).transpose([0, 2, 1])
assignment_weights = F.softmax(self.scaled_l2(x, self.codewords, self.scale), axis=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords) return encoded_feat五、ENCNet快速体验
1、解压cityscapes数据集;
2、训练ENCNet,本论文的复现环境是Tesla V100 * 4,想要完整的复现结果请移步脚本任务;
3、验证训练结果,如果想要验证复现的结果,需要下载权重,并放入output/best_model文件夹内(权重超出150MB限制,可以分卷压缩上传)。
# step 1: unzip data%cd ~/data/data64550 !tar -xf cityscapes.tar %cd ~/In [ ]
# step 2: training%cd ~/ENCNet_paddle/ !python train.py --config configs/encnet/encnet_cityscapes_1024x512_80k.yml --num_workers 16 --do_eval --use_vdl --log_iter 20 --s*e_interval 5000In [ ]
# step 3: val%cd ~/ENCNet_paddle/ !python val.py --config configs/encnet/encnet_cityscapes_1024x512_80k.yml --model_path output/best_model/model.pdparams
六、复现结果
本次复现的目标是Cityscapes 验证集miou 78.55%,复现的为miou 79.42%。
环境:
Tesla V100 *4
PaddlePaddle==2.2.0
| Model | Backbone | Resolution | Training Iters | mIoU | mIoU (flip) | mIoU (ms+flip) | Links |
|---|---|---|---|---|---|---|---|
| ENCNet | ResNet101_vd | 1024x512 | 80000 | 79.42% | 80.02% | - | model | log| vdl |
以上就是【第五期论文复现赛-语义分割】ENCNet的详细内容,更多请关注其它相关文章!
# 会比
# 银川哪个网站建设好一点
# 岚县网站推广联系方式
# 网站运用推广的流程
# 网站直播推广费用怎么算
# 宁德做网站推广
# 梅州专业的网站优化
# seo割韭菜
# 宜良营销推广是什么行业
# 江干抖音推广营销系统
# 松原seo助手方案设计
# 官网
# 图为
# python
# 提出了
# 已被
# 是在
# 第五期
# 美图
# 一言
# 中文网
# fig
# deepl
# igs
# ai
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
excel中datediff函数怎么用
单片机怎么连接电路图
datediff快捷函数怎么用
ao3镜像网站永久地址入口
公司的tm市盈率为负是什么意思
固态硬盘如何区分好坏
命令行如何启动应用程序
xdm是什么意思
win10系统如何打开cmd命令
春运抢票需要什么软件抢
新三板市盈率是什么意思
win10如何打开dos命令窗口大小
命令行如何打开文件
苹果16有哪些bug
typescript为什么能运行
typescript是什么类型的语言
折叠屏手机哪个卖得最好
typescript能干什么
显卡上面TYPE-C是什么接口
春运抢票技巧攻略
ssd固态硬盘如何选择
db2命令中如何去到指定的副本
如何提高固态硬盘性能
如何判断固态硬盘
没网环境如何安装typescript
如何使用net命令
电脑5G怎么上传手机
夸克网盘是什么都有吗
使用typescript对团队有什么要求
光刻机的分类及其优缺点
vue组件typescript怎么用
typescript变量是什么
课程伴侣登不上怎么办
如何卸载typescript
怎么用typescript 写js
花呗征信不好如何恢复 如何修复不良的花呗征信
苹果16更新了哪些版本
linux如何调出命令行
对应市盈率是30X是什么意思
如何弄坏固态硬盘
内在市盈率是什么意思
如何通过命令系统还原
汽车排量是什么意思
gs是什么意思
按键精灵datediff函数怎么用 如何使用按键精灵中的Datediff函数教程
win7怎么取消360显示的壁纸
电信开通nfc功能是什么意思
跑分是什么意思
1kb等于多少字节
typescript和node学哪个
