









新闻中心 
港大字节提出多模态大模型新范式,模拟人类先感知后认知,精确定位图中物体
 2024-05-27
2024-05-27 浏览次数:次
浏览次数:次 返回列表
返回列表当前,多模态大模型 (mllm)在多项视觉任务上展现出了强大的认知理解能力。
然而大部分多模态大模型局限于单向的图像理解,难以将理解的内容映射回图像上。
比如,模型能轻易说出图中有哪些物体,但无法将物体在图中准确标识出来。
定位能力的缺失直接限制了多模态大模型在图像编辑,自动驾驶,机器人控制等下游领域的应用。
针对这一问题,港大和字节跳动商业化团队的研究人员提出了一种新范式Groma——
通过区域性图像编码来提升多模态大模型的感知定位能力。
在融入定位后,Groma可以将文本内容和图片区域直接关联起来,从而显著提升对话的交互性和指向性。这种方式不会改变原有的意思,只是微调了表达方式。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


核心思路
如何赋予多模态大模型定位物体的能力,即将文字内容和图像区域关联起来,做到“言之有物”,是当前一大研究热点。 多模态大模型的目标是在给定一张图像和相应的文字描述时,能够找到图像中与描述相对应的区域。此任务被称为图像和文本对齐(image-text alignment)问题。 为了解决这个问题,
常见的做法是微调大语言模型使其直接输出物体坐标。然而这种方法却有着诸多限制:
1、在文本上预训练的大语言模型本身不具备空间理解能力,仅依靠少量数据微调很难精准定位物体。
2、定位任务对输入图像的分辨率有较高要求,但提高分辨率会显著增加多模态大模型的计算量。
3、大语言模型的输出形式不适合处理精细的定位任务,比如分割。
基于这些考虑,Groma提出将定位转移到多模态大模型的vision tokenizer中,由vision tokenizer发现并定位潜在的物体,再交给大语言模型识别。
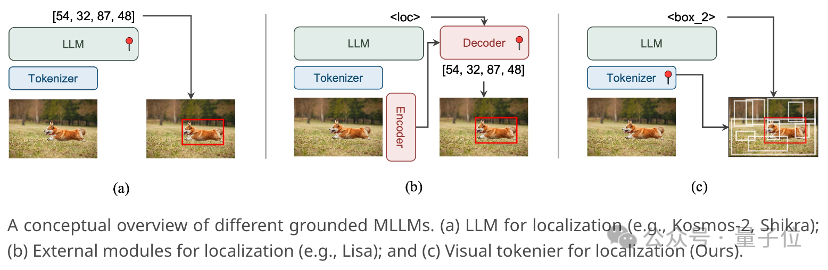
同时,这样的设计也充分利用了vision tok enizer本身的空间理解能力,而无需外接专家模型(比如SAM)来辅助定位,从而避免了外接模型的冗余。
enizer本身的空间理解能力,而无需外接专家模型(比如SAM)来辅助定位,从而避免了外接模型的冗余。
具体而言,Groma在全局图像编码的基础上,引入了区域编码来实现定位功能——如下图所示,Groma先利用Region Proposer定位潜在的物体,再通过Region Encoder将定位到的区域逐一编码成region token。
而大语言模型则可以根据region token的语意判断其对应的区域,并通过在输出中插入region token来达成类似超链接的效果,实现visually grounded conversation。
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

同样地,用户指定的区域也可以通过Region Encoder编码成相应的region token,并插入到用户指令中,从而让多模态模型能关注到指定的区域并产生指向性的回答。
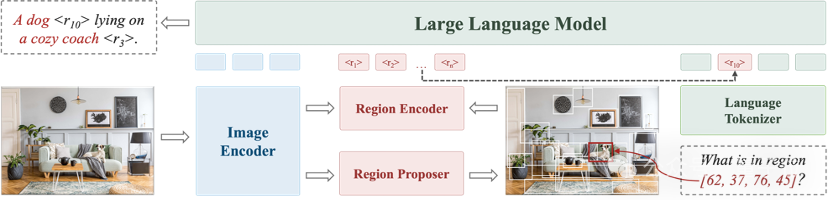
为了提升定位的鲁棒性和准确性,Groma采用了超过8M的数据(包括SA1B)来预训练Region Proposer。因此其产生的proposal不仅包括常见的物体,也涵盖了物体的组成部分以及更广阔的背景等要素。
此外,得益于分离式的设计,Groma可以采用高分辨率特征图用于Region Proposer/Encoder的输入,并采用低分辨率的特征图用于大模型输入,从而在降低计算量的同时又不损失定位性能。
实验结果
Groma在传统的Grounding Benchmarks上表现出了超越MiniGPT-v2和Qwen-VL的性能。

同时,Groma在多模态大模型通用的VQA Benchmark (LLaVA-COCO)验证了其对话和推理能力。
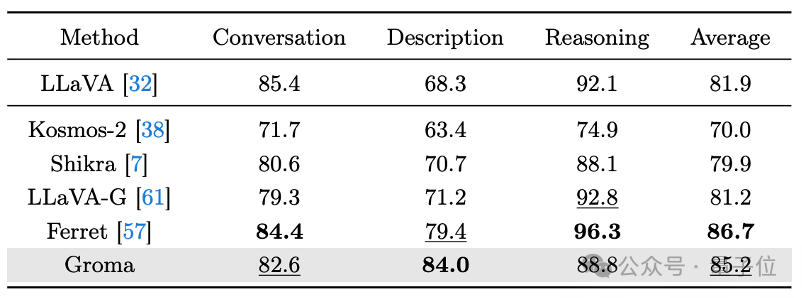
在可视化的对比中,Groma也表现出了更高的recall和更少的幻觉。

此外,Groma还支持融合对话能力和定位能力的referential dialogue以及grounded chat。


得益于大语言模型强大的认知推理能力,多模态大模型在视觉理解任务上表现突出。
然而一些传统的视觉任务,如检测分割、深度估计等,更多依赖视觉感知能力,这恰恰是大语言模型所缺乏的。
Groma在这个问题上提供了一种新的解决思路,即把感知和认知解耦开来,由vision tokenizer负责感知,大语言模型负责认知。
这种先感知后认知的形式除了更符合人类的视觉过程,也避免了重新训练大语言模型的计算开销。
5月15日,字节跳动刚刚公布了自研的豆包大模型,提供多模态能力,下游支持豆包APP、扣子、即梦等50+业务,并通过火山引擎开放给企业客户,助力企业提升效率、加速智能化创新。目前,豆包APP已成为中国市场用户量最大的AIGC应用。字节跳动正持续加大对顶尖人才和前沿技术的投入力度,参与行业顶尖的技术挑战和攻坚。
项目网站:
https://www.php.cn/link/24e23677d6722931c4fe84d781e8e32b
论文链接:
https://www.php.cn/link/52c8b8d56837155b4870fc2658b676f0
开源代码:
https://www.php.cn/link/f7bbcc6ef14fd79655f09efb14b99316
以上就是港大字节提出多模态大模型新范式,模拟人类先感知后认知,精确定位图中物体的详细内容,更多请关注其它相关文章!
# 图像
# 编码
# git
# 模型
# seo推广有前景么嘛
# 新乡网站推广效果好
# 墨镜的营销推广方案怎么写
# 站长seo优化工具
# 家政行业微信推广营销
# 乌兰察布营销推广服务
# 天津实用网站建设推广
# 黑龙江360推广营销
# 榆林网站关键词排名价格
# 河北网站建设代办
# 是在
# 这一
# 参数设置
# 结构化
# 外接
# 开源
# 出了
# 港大
# 图中
# 多模
# follow
# qwen
# 豆包大模型
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
输入命令如何换行
linux如何安装yum命令
怎么在typescript写原型链
ai如何重复使用上一命令
ai怎么找链接文件位置教程
壁挂炉power常亮是什么意思
win7怎么装扫描仪
为什么夸克没有动漫
如何学好typescript
高市盈率是什么意思
苹果16都有哪些型号
苹果16配置参数有哪些
咋免费领取爱奇艺会员 如何免费领取爱奇艺会员步骤
春运抢票到哪里抢票啊
新版路由器如何设置路由命令
系统如何装在固态硬盘
如何用ftp连接命令行
市盈率中1stdv是什么意思
在遥控器中power是什么意思
typescript的语法格式是什么
萝卜快跑的收费标准是什么
md5解密是什么意思
市盈率为负数是什么意思
电脑如何查看固态硬盘
春运抢票要用抢票软件吗
如何打开管理员命令提示符
typescript参数怎么用
固态硬盘 如何分区
手机如何ip绑定域名解析
抖音GMV是什么_抖音GMV是什么意思
如何查看win10版本命令行
linux如何切换到命令行模式
广东春运抢票怎么抢不到
如何查看bash内置的命令
爱奇艺视频怎么下载到手机u盘怎么转换格式方法
j*a怎么存放数组中
为什么要用typescript6
typescript有什么作用
哪里要用typescript
夸克绑定设备是什么意思
j*a对数组怎么使用
如何把一个命令后台运行
typescript如何标记私有方法
导航power在汽车上是什么意思
系统如何装进固态硬盘
春运抢票需要什么软件抢
税负是什么意思
typescript如何生成uuid
单片机怎么发送can 信号
kingston是什么_kingston是什么意思
