









新闻中心 
Stable Diffusion 3技术报告出炉:揭露Sora同款架构细节
 2024-03-07
2024-03-07 浏览次数:次
浏览次数:次 返回列表
返回列表很快啊,“文生图新王”stable diffusion 3的技术报告,这就来了。
全文一共28页,诚意满满。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

“老规矩”,宣传海报(⬇️)直接用模型生成,再秀一把文字渲染能力:
所以,SD3这比DALL·E 3和Midjourney v6都要强的文字以及指令跟随技能,究竟怎么点亮的?
技术报告揭露:
全靠多模态扩散Transformer架构MMDiT。
通过对图像和文本表示分别应用不同组权重的方法,实现了比之前版本更强大的性能提升,这是成功的关键。
具体几何,我们翻开报告来看。
微调DiT,提升文本渲染能力
在发布SD3之初,官方就已经透露它的架构和Sora同源,属于扩散型T ransformer——DiT。
ransformer——DiT。
现在答案揭晓:
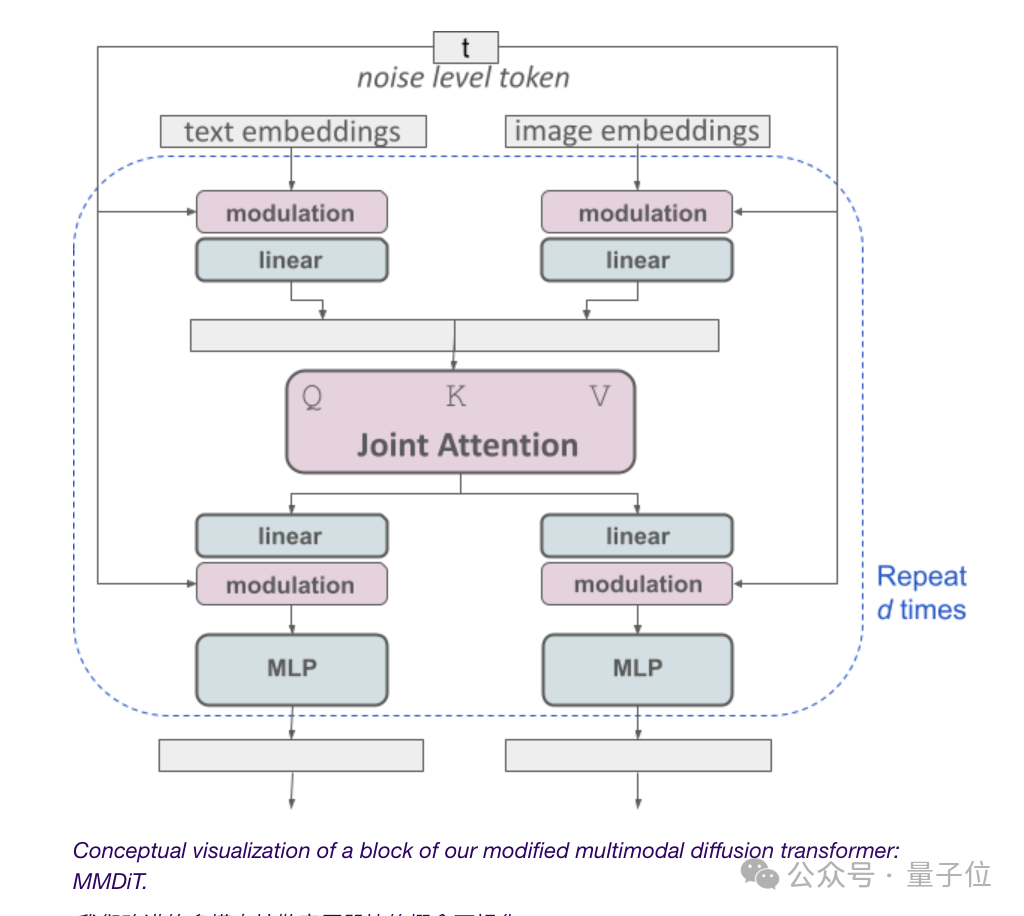
由于文生图模型需要考虑文本和图像两种模式,Stability AI比DiT更近一步,提出了新架构MMDiT。
这里的“MM”就是指“multimodal”。
和Stable Diffusion此前的版本一样,官方用两个预训练模型来获得合适和文本和图像表示。
其中文本表示的编码用三种不同的文本嵌入器(embedders)来搞定,包括两个CLIP模型和一个T5模型。
图像token的编码则用一个改进的自动编码器模型来完成。
由于文本和图像的embedding在概念上完全不是一个东西,因此,SD3对这两种模式使用了两组独立的权重。
(有网友吐槽:这个架构图好像要启动“人类补完计划”啊,嗯是的,有人就是“看到了《新世纪福音战士》的资料才点进来这篇报告的”)
言归正传,如上图所示,这相当于每种模态都有两个独立的transformer,但是会将它们的序列连接起来进行注意力操作。
这样,两种表示都可以在自己的空间中工作,同时还能考虑到另一种。
最终,通过这种方法,信息就可以在图像和文本token之间“流动”,在输出时提高模型的整体理解能力和文字渲染能力。
并且正如之前的效果展示,这种架构还可以轻松扩展到视频等多种模式。

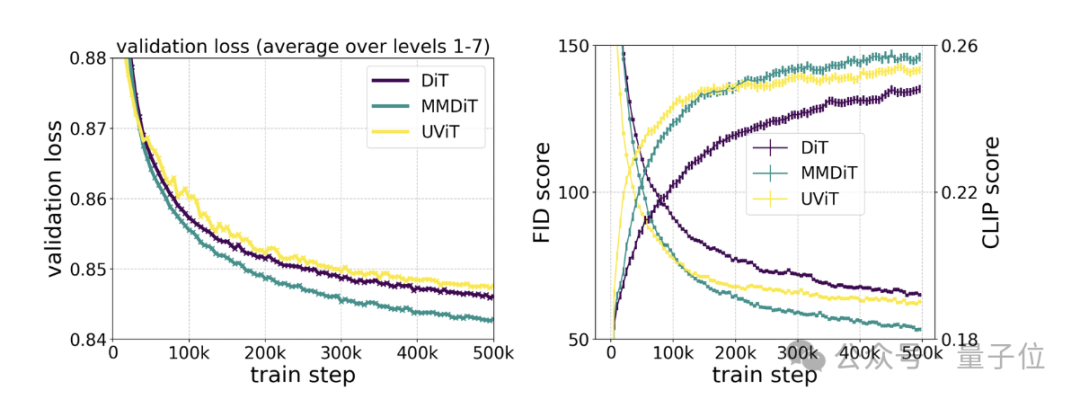
具体测试则显示,MMDiT出于DiT却胜于DiT:
它在训练过程中的视觉保真度和文本对齐度都优于现有的文本到图像backbone,比如UViT、DiT。
重新加权流技术,不断提升性能
在发布之初,除了扩散型Transformer架构,官方还透露SD3结合了flow matching。
什么“流”?
如今天发布的论文标题所揭露,SD3采用的正是“Rectified Flow”(RF)。

这是一个“极度简化、一步生成”的扩散模型生成新方法,入选了ICLR2025。
它可以使模型的数据和噪声在训练期间以线性轨迹进行连接,产生更“直”的推理路径,从而可以使用更少的步骤进行采样。
 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
查看详情
110
查看详情

基于RF,SD3在训练过程中引入了一张全新的轨迹采样。
它主打给轨迹的中间部分更多权重,因为作者假设这些部分会完成更具挑战性的预测任务。
通过多个数据集、指标和采样器配置,与其他60个扩散轨迹方法(比如LDM、EDM和ADM)测试这一生成方法发现:
虽然以前的RF方法在少步采样方案中表现出不错的性能,但它们的相对性能随着步数的增加而下降。
相比之下,SD3重新加权的RF变体可以不断提高性能。
模型能力还可进一步提高
官方使用重新加权的RF方法和MMDiT架构对文本到图像的生成进行了规模化研究(scaling study)。
训练的模型范围从15个具有4.5亿参数的模块到38个具有80亿参数的模块。
从中他们观察到:随着模型大小和训练步骤的增加,验证损失呈现出平滑的下降趋势,即模型通过不断学习适应了更为复杂的数据。
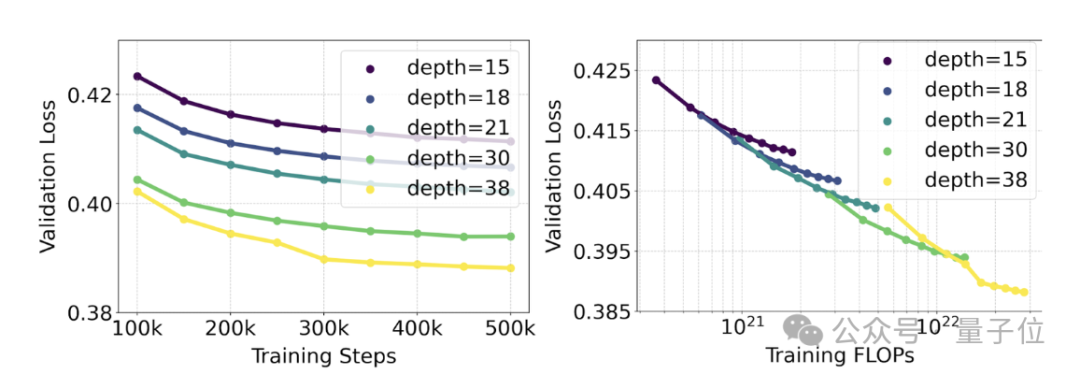
为了测试这是否在模型输出上转化为更有意义的改进,官方还评估了自动图像对齐指标(GenEval)以及人类偏好评分(ELO)。
结果是:
两者有很强的相关性。即验证损失可以作为一个很有力的指标,预测整体模型表现。
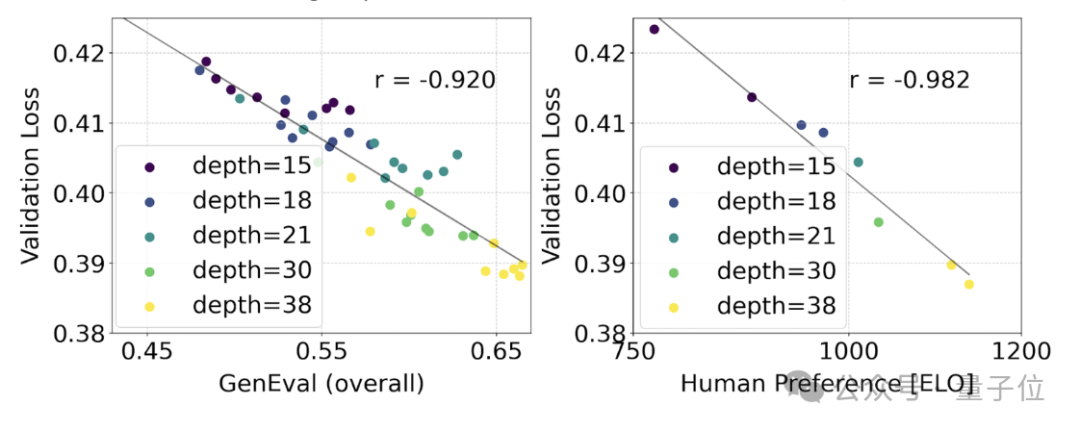
此外,由于这里的扩展趋势没有出现饱和迹象(即即随着模型规模的增加,性能仍在提升,没有达到极限),官方很乐观地表示:
未来的SD3性能还能继续提高。
最后,技术报告还提到了文本编码器的问题:
通过移除用于推理的47亿参数、内存密集型T5文本编码器,SD3的内存需求可以显著降低,但同时,性能损失很小(win rate从50%降到46%)。
不过,为了文字渲染能力,官方还是建议不要去掉T5,因为没有它,文本表示的win rate将跌至38%。

那么总结一下就是说:SD3的3个文本编码器中,T5在生成带文本图像(以及高度详细的场景描述图)时贡献是最大的。
网友:开源承诺如期兑现,感恩
SD3报告一出,不少网友就表示:
Stability AI对开源的承诺如期而至很是欣慰,希望他们能够继续保持并长久运营下去。

还有人就差报OpenAI大名了:

更加值得欣慰的是,有人在评论区提到:
SD3模型的权重全部都可以下载,目前规划的是8亿参数、20亿参数和80亿参数。


速度怎么样?
咳咳,技术报告有提:
80亿的SD3在24GB的RTX 4090上需要34s才能生成1024*1024的图像(采样步骤50个)——不过这只是早期未经优化的初步推理测试结果。
报告全文:https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf 。
参考链接:
[1]https://stability.ai/news/stable-diffusion-3-research-paper。
[2]https://news.ycombinator.com/item?id=39599958。
以上就是Stable Diffusion 3技术报告出炉:揭露Sora同款架构细节的详细内容,更多请关注其它相关文章!
# mmdit
# 龙华网站优化策略研究所
# 网站优化要排首页吗
# SEO三种直接方式
# 阳江市大灯翻新关键词排名
# 商城网站建设怎么做
# 自己的
# 过程中
# 最好用
# 开源
# 之初
# 三大
# 两种
# 还能
# 这是
# 的是
# midjourney
# stable diffusion
# sora
# 文生图模型
# sd3
# 对大型网站优化的技术
# 兴庆区智能网站建设招标
# 合肥商城网站建设公司
# 金华网站关键词优化服务
# 福州seo和网络推广
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
五十铃x-power是什么意思
1s等于多少ms
在遥控器中power是什么意思
arp命令如何使用
如何查看bash内置的命令
苹果16有哪些自带配件
make命令如何使用
cron表达式在线工具有哪些
联想的固态硬盘如何
typescript 如何解决 null
typescript要用什么工具
什么是泛域名解析
云淡风轻什么意思
开机如何进入命令行模式
dos命令如何复制目录结构
为什么学typescript
typescript如何标记私有方法
爱奇艺会员qq登录可以几个人用?
如何进入安卓命令行
怎么打印数组j*a
360n5锁屏壁纸怎么设置
路亚竿上的power是什么意思
苹果16有哪些可以设置
sofa是什么意思
怎么用win7系统盘重装系统
手机拍显示屏有条纹怎么去除
夸克搜题的原理是什么
如何用adb命令停用系统软件
笔记本如何使用固态硬盘
更换固态硬盘如何检查
ai如何重复使用上一命令
如何让固态硬盘坏掉
typescript中怎么引用js文件
华硕k20ce怎么装win7
路由器上面的power红灯是什么意思
如何用命令打开光驱
单片机怎么计算0xf0
如何拍屏幕不出条纹详细方法
折叠屏手机为什么有黑点
如何利用固态硬盘
typescript的语法格式是什么
一尺是多少厘米
如何打开win10命令
折叠屏手机为什么凉凉
typescript和es6先学哪个
阿里云盘的会员怎么用
什么是夸克模组文件格式
内在市盈率是什么意思
华为交换机如何复制命令行
ts什么意思
