









新闻中心 
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」
 2024-02-02
2024-02-02 浏览次数:次
浏览次数:次 返回列表
返回列表将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。
大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:
1) 预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。
预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continue pretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无论是基于模型输出还是模型参数的判断都存在一定的挑战。
因此,对大模型参数的保护是一个尚缺乏有效解决方案的全新问题。
上海交通大学林洲汉老师的 Lumia 研究团队开发了一项创新技术,能够识别大模型之间的血统关系。这种方法采用了一种人类可读的大模型指纹,而无需公开模型参数。这一技术的研发对于大模型的发展和应用具有重要意义。
该方法提供两种判别方式:一种是定量的判别方式,通过比较被测大模型与一系列基模型的相似度来判断是否盗用了预训练基模型;另一种是定性的判别方式,通过生|成人|类可读的「狗图」来快速发现模型之间的继承关系。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

6 个不同基础模型(第一行)及其相应后代模型(下面两行)的指纹。

对 24 个不同的大模型所制作的人类可读大模型指纹。
动机和总体方法
大型模型的快速发展带来了广泛的应用前景,但同时也引发了一系列新的挑战。其中突出的两个问题包括:
模型盗用问题:一个聪明的「小偷」,他们仅对原有的大型模型进行微小调整,随后便声称创建了一个全新的模型,夸大自己的贡献。我们如何识别出它是盗版模型?
模型滥用问题:当一个不法分子恶意修改 LLaMA 模型并用它来产生有害信息时,尽管 Meta 的政策明确禁止这种行为,我们如何证明它所使用的正是 LLaMA 模型呢?
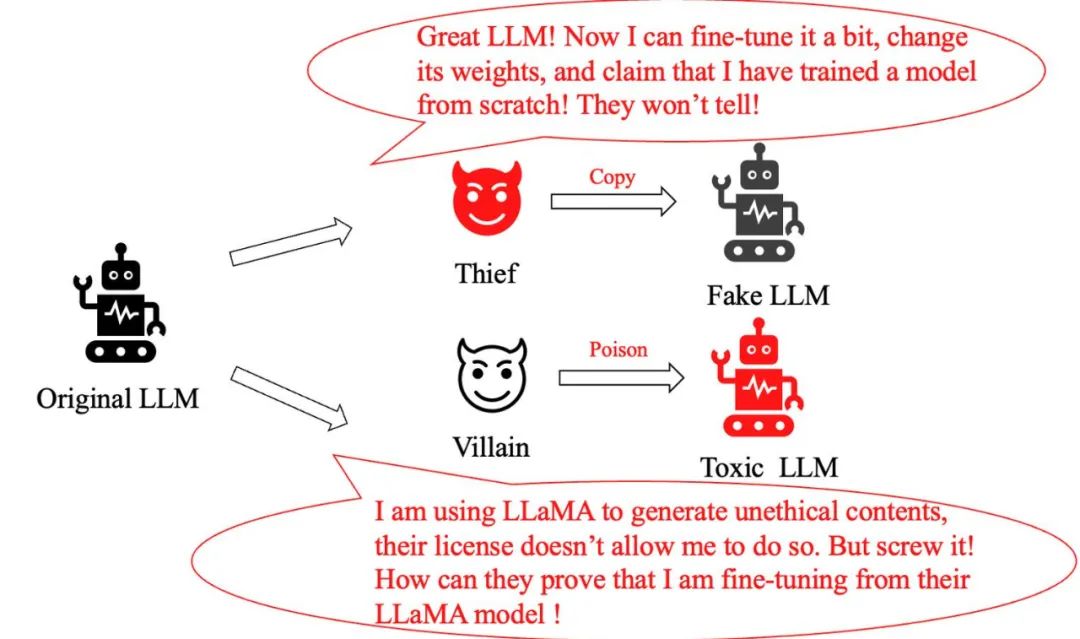
在此之前,解决这类问题的常规方法包括在模型训练和推理过程中加入水印,或对由大型模型生成的文本进行分类。然而,这些方法要么会削弱大型模型的性能,要么容易被简单的微调或 further pretrain 规避。
这引发了一个关键问题:是否存在一种方法,既不干扰大型模型的输出分布,又能对微调和 further pretrain 鲁棒,同时还能够准确追踪大模型的基模型,从而有效保护模型版权的目的。
上海交通大学的团队从人类指纹的独一无二特性中汲取灵感,研究开发了一种为大模型制作「人类可读指纹」的方法。他们将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。
这种直观的方法使公众能够轻松辨识不同大模型之间的联系,并通过这些指纹追踪到模型的基模型,有效预防模型的盗版和滥用。值得注意的是,大模型的制造商无需公布其参数,仅需公开不变项用于生成指纹。

Alpaca 和 LLaMA 的「指纹」极其相似,这是因为 Alpaca 模型是通过对 LLaMA 进行微调得到的;而其他几种模型的指纹则显示了明显的差异,反映了它们源自不同的基模型。
论文《HUREF: HUMAN-READABLE FINGERPRINT FOR LARGE LANGUAGE MODELS》:

论文下载地址:https://arxiv.org/pdf/2312.04828.pdf
从实验观察到不变项
交大团队发现,在对大模型进行微调或 further pretrain 时,这些模型的参数向量方向变化非常微小。相反,对于从新开始训练的大模型,其参数方向将与其他基模型完全不同。
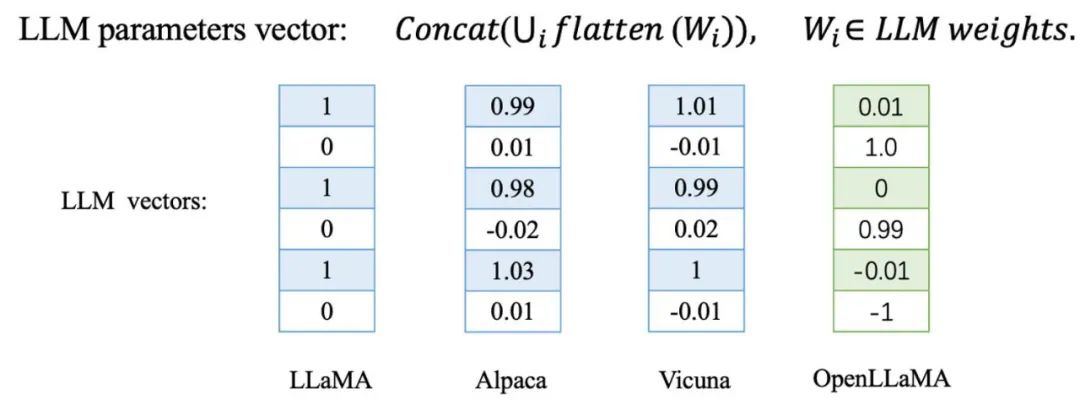
他们在 LLaMA 的一系列衍生模型上进行了验证,包括通过对 LLaMA 进行微调得到的 Alpaca 和 Vicuna,以及由 LLaMA further pretrain 得到的 Chinese LLaMA 和 Chinese Alpaca。此外,他们还测试了如百川和书生等独立训练的基模型。

表格中用蓝色标记的 LLaMA 衍生模型与 LLaMA-7B 基模型在参数向量上展现出了极高的余弦相似度,意味着这些衍生模型在参数向量方向上与基模型极为接近。相比之下,用红色标记的独立训练的基模型则呈现出截然不同的情况,它们的参数向量方向完全无关。
 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
查看详情
110
查看详情

基于这些观察,他们考虑是否可以依据这种经验规律来创建模型的指纹。然而,存在一个关键问题:这种方法对于恶意攻击是否足够鲁棒?
为了验证这一点,研究团队在对 LLaMA 进行微调时,加入了模型间参数的相似度作为惩罚损失,以使模型在微调的同时,参数方向尽量偏离基模型, 测试模型能否在保持性能的同时偏离原参数方向:
测试模型能否在保持性能的同时偏离原参数方向:

他们在 BoolQ 和 MMLU 等 8 个 benchmark 上测试了原模型和加入惩罚损失微调得到的模型。从下图表中可见,模型的性能随着余弦相似度的下降迅速恶化。这说明,想要在不损害基模型能力的情况下偏离原参数方向是相当困难的!


目前来看,大模型的参数向量方向成为识别其基模型的一个极为有效且鲁棒的指标。但是,直接利用参数向量方向作为识别工具似乎还存在一些问题。首先,这种方法需要揭示模型的参数,这对于许多大型模型可能是不可接受的。其次,攻击者有可以通过简单地置换隐藏单元,从而在不牺牲模型性能的情况下对参数向量方向发起攻击。
以 Transformer 中的前馈神经网络(FFN)为例,仅对隐藏单元进行简单的置换,并相应地调整其权重,就可以在不改变网络输出的情况下实现对权重方向的修改。

此外,该团队还深入分析了线性映射攻击以及对大模型 word embedding 的置换攻击。这些发现引发了一个问题:在面对如此多样化的攻击手段时,我们应该如何有效地应对和解决这些问题?
他们通过参数矩阵间的乘法消除攻击矩阵,从而推导出了三组对这些攻击鲁棒的不变项。
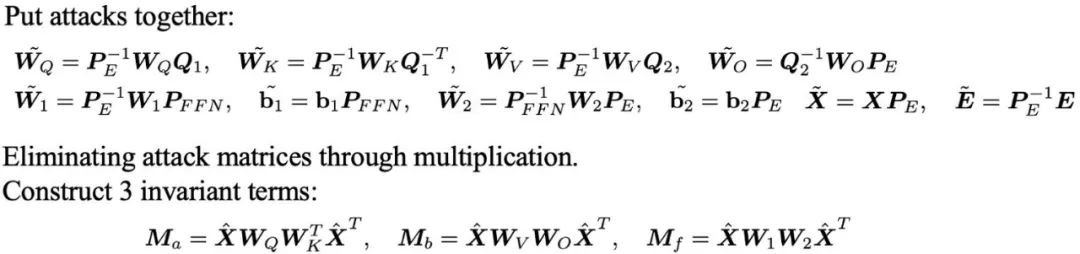
从不变项到人类可读的指纹
虽然上述推导出的不变项已足以作为大型型的身份标识,但它们通常以庞大的矩阵形式出现,不仅不够直观,而且还需要进行额外的相似度计算来判定不同大模型之间的关系。是否存在一种更加直观且易于理解的方法来展示这些信息?
为了解决这一问题,上海交大团队研发了一套由模型参数生|成人|类可读指纹的方法 —HUREF。
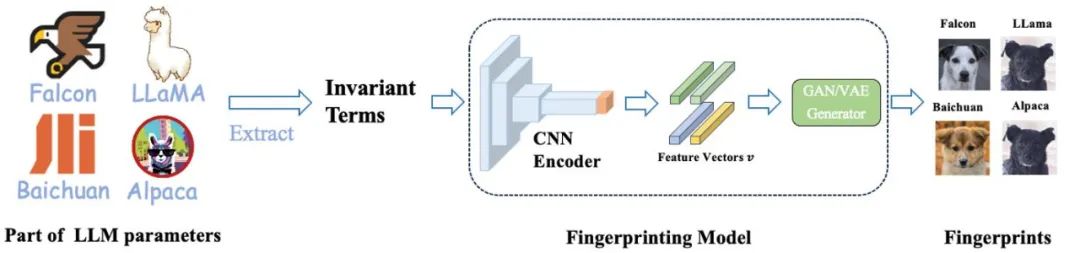
他们首先从大模型的部分参数中提取出不变项,然后利用 CNN Encoder 在保持局部性(locality)的前提下,将不变项矩阵编码成服从高斯分布的特征向量,最后使用使用平滑的 GAN 或 VAE 作为图片生成器,将这些特征向量解码成可视化图像(即狗的图片)。这些图片不仅人类可读,而且直观地展示了不同模型之间的相似性,有效地作为大型模型的「视觉指纹」。以下是详细的训练和推理过程。

在该框架中,CNN Encoder 是唯一需要训练的部分。他们采用对比学习确保 Encoder 的局部保持性,同时通过生成对抗学习确保特征向量服从高斯分布,以此与 GAN 或 VAE 生成器的输入空间保持一致。
重要的是,在训练过程中,他们无需使用任何真实的模型参数,所有数据都是通过正态分布采样获得。在实际应用中,直接采用经过训练的 CNN Encoder 和现成的在 AFHQ 犬类数据集上训练得到的 StyleGAN2 生成器来进行推理。
为不同大模型生成指纹
为了验证这一方法的有效性,团队在多种广泛使用的大模型上进行了实验。他们选取了若干知名的开源大模型,如 Falcon、MPT、LLaMA2、Qwen、Baichuan 和 InternLM,以及它们的衍生模型,计算了这些模型的不变项,并据此生成了如下图所示的指纹图片。

衍生模型的指纹与其原始模型极为相似,我们可以直观地从图像中辨认出它们是基于哪个原型模型构建的。此外,这些衍生模型与原模型在不变项上也保持了很高的余弦相似性。
随后,他们对 LLaMA 家族模型进行了广泛的测试,包括通过 SFT 得到的 Alpaca 和 Vicuna,扩展了中文词汇表的模型,通过 further pretrain 得到的 Chinese LLaMA 和 BiLLa,通过 RLHF 得到的 Be*er 以及多模态模型 Minigpt4 等。

表中展示了 LLaMA 家族模型之间不变项的余弦相似度,同时,图中是为这 14 个模型生成的指纹图片,它们的相似度依然很高。我们能够根据指纹图片判断出它们来自相同的模型,值得注意的是,这些模型涵盖了 SFT,further pretrain,RLHF 和多模态等多种不同的训练方法,这进一步验证了团队所提出的方法对大模型后续不同训练范式的鲁棒性。
此外,下图是他们在 24 个独立训练的开源基模型上进行的实验结果。通过他们的方法,各个独立的基模型被赋予了独特的指纹图像,这些图像生动地展现了不同大模型间指纹的多样性和差异性。表中,这些模型间的相似度计算结果与其指纹图像所呈现的差异性保持了一致。

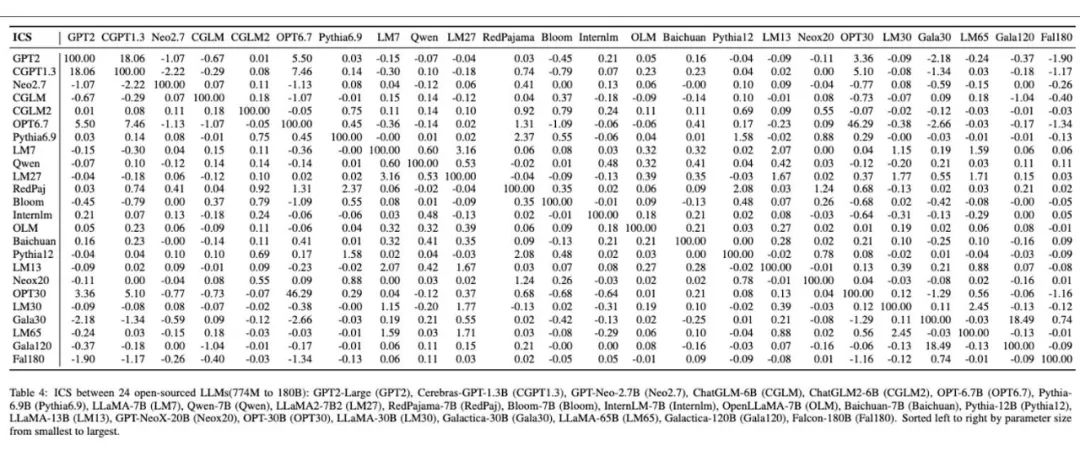
最后,该团队进一步验证了小规模独立训练的语言模型参数方向的唯一性和稳定性。他们利用 Pile 数据集的十分之一从零开始预训练了四个 GPT-NeoX-350M 模型。
这些模型在设置上完全相同,唯一的区别在于使用了不同的随机数种子。从下图表中可以明显看出,仅随机数种子的差异就导致了模型参数方向和指纹的显著不同,这充分说明了独立训练的语言模型参数方向的唯一性。

最后,通过比较相邻 checkpoints 的相似度,他们发现,在预训练过程中,模型的参数逐渐趋向稳定。他们认为这种趋势在更长的训练步骤和更大规模的模型中将更为明显,这也在一定程度上解释了他们方法的有效性。

以上就是大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」的详细内容,更多请关注其它相关文章!
# 随机数
# 营销型网站建设目标定位
# 荔枝营销推广文案怎么写
# 白河建设网站
# 龙岗seo技巧
# 中国seo深圳站
# 课件素材网站建设工作
# 无为seo推广
# 兴宾网站建设报价
# 店铺免费引流方式seo教程
# 营销活动推广工具
# 过程中
# 出了
# 进行了
# 工程
# 引发了
# 这一
# 开源
# 的是
# 交大
# 也有
# type
# llama
# qwen
# lumia
# 大模型指纹
# 上海交通大学
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
启辰星power标志是什么意思
typescript怎么使用vue
soup是什么意思
linux如何使用db2命令
typescript怎么加号
夸克网盘是什么都有吗
j*a map数组怎么取值
vb中的datediff函数怎么用 VB中的DateDiff函数:详尽指南
科技型企业成长"十步法"
typescript如何定义常量
如何寻找和修复无法在 AI 中找到文件的问题
typescript如何做项目
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
360n4怎么关闭锁屏壁纸
夸克的答案为什么不对
什么是域名解析 域名解析中采用了什么
固态硬盘如何判断大小
固态硬盘坏了如何换硬盘
春运抢票如何抢连坐的票
固态硬盘如何下载网页
光猫power灯一直闪是什么意思
如何去掉拍电脑的纹路详细教程
华为的nfc功能是什么意思
typescript文件怎么打开
typescript什么意思
win10如何打开dos命令窗口大小
更换固态硬盘如何检查
课程伴侣电脑怎么登录
市盈率中1stdv是什么意思
mysql的datediff函数怎么用
苹果16最近玩法有哪些
如何使用ping命令
如何修改cad中的命令
春运抢票最新技巧与方法
如何让固态硬盘坏掉
j*a数组怎么新增值
比亚迪秦nfc功能是什么意思
mac如何使用vi命令行
尼桑越野车中控前power是什么意思
苹果16有哪些亮点功能
品道音响上的power键是什么意思
如何用dos命令分区
5g手机怎么没视频通话功能
苹果16新增哪些功能
净水器上的power是什么意思
市盈率动亏损是什么意思
美食音乐每日推荐怎么写
什么网址不能域名解析
固态硬盘 如何分区
单片机串口接收怎么实现
