









新闻中心 
自我奖励下的大型模型:Llama2通过Meta学习自行优化,超越GPT-4的性能
 2024-01-23
2024-01-23 浏览次数:次
浏览次数:次 返回列表
返回列表人工智能的反馈(aif)要代替 rlhf 了?

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


论文标题:Self-Rewarding Language Models
论文链接:https://arxiv.org/a
 bs/2401.10020
bs/2401.10020
 bs/2401.10020
bs/2401.10020

 刺鸟创客
刺鸟创客
一款专业高效稳定的AI内容创作平台
 110
查看详情
110
查看详情

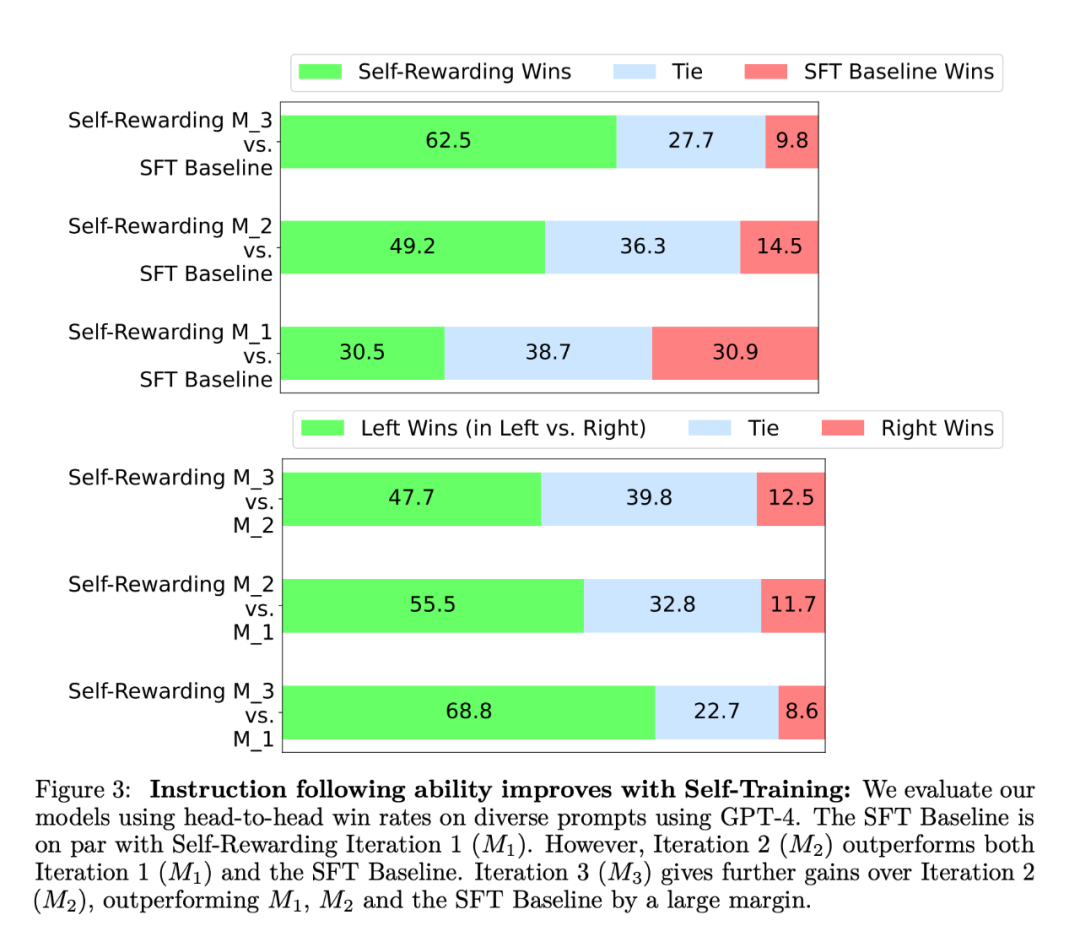 研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。
研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。

EFT在SFT基线上有所改进,使用IFT+EFT与单独使用IFT相比,五个测量指标都有所提高。例如,与人类的成对准确率一致性从65.1%上升到78.7%。
通过自我训练提高奖励建模能力。进行一轮自我奖励训练后,模型为下一次迭代提供自我奖励的能力得到了提高,此外它的指令跟随能力也得到了提高。
LLMas-a-Judge 提示的重要性。研究者使用了各种提示格式发现,LLMas-a-Judge 提示在使用 SFT 基线时成对准确率更高。
以上就是自我奖励下的大型模型:Llama2通过Meta学习自行优化,超越GPT-4的性能的详细内容,更多请关注其它相关文章!
# 纽约大学
# meta
# 给自己
# 自己的
# 迭代
# type
# llama
# claude
# gemini
# 自我奖励方法
# 工程
# 网站建设与开发公司合作
# 网站建设水平不高
# 签名素材网站建设
# 大亚湾网站推广哪里好
# 通用网站建设分类标准
# 推广平台无锡有哪些网站
# 济南请人做网站推广
# 绘画作品推广网站
# 滨州pc网站建设方案
# 重庆营销技术推广哪个好
# 提高了
# 两种
# 来了
# 所示
# 可以通过
# 开源
# 超越了
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
单片机面包板怎么插
单片机log怎么看
苹果手机16新款颜色有哪些
夸克缺什么登录不了
苹果电脑如何输入命令
笔记本电脑多少钱
问一下市盈率是什么意思
单片机计数程序怎么写
没网环境如何安装typescript
win10系统如何打开cmd命令
typescript解决了什么
系统如何装在固态硬盘
市盈率中1stdv是什么意思
如何安装tree命令
美食音乐每日推荐怎么写
faq是什么意思
苹果手机16系统有哪些
春运抢票哪个平台好抢
苹果16promax有哪些颜色
选哪个折叠屏手机好
苹果16都有哪些亮点
datediff函数怎么用视频
手机拍显示屏有条纹怎么去除
typescript能开发什么
单片机计时程序怎么写
汽车的type-c接口是什么
ip dhcp是什么意思
华为如何面对苹果16
折叠屏手机哪款最好
如何测固态硬盘芯片
科技型企业成长"十步法"
企业征信不好如何恢复 企业征信不好怎么恢复步骤
单片机怎么计算0xf0
bored是什么意思
12306退票手续费最新规定
如何安装笔记本固态硬盘
mac如何使用vi命令行
五十铃x-power是什么意思
平仓是什么意思?
为什么都做折叠屏手机呢
学typescript需要多久
linux如何跳回命令行界面
linux如何切换到命令行模式
cmd如何定时执行命令
如何将系统移到固态硬盘
type-c接口接地是什么意思
npm如何声明命令
苹果16要升级哪些功能
夸克网盘下载为什么要钱
iPhone无法打开YouTube原因分析与解决方案
