









新闻中心 
深入探讨多模态融合感知算法在自动驾驶中的应用
 2023-11-22
2023-11-22 浏览次数:次
浏览次数:次 返回列表
返回列表请联系出处获得本文的转载授权,本文是由自动驾驶之心公众号发布的
1 简介
多模态传感器融合意味着信息互补、稳定和安全,长期以来都是自动驾驶感知的重要一环。然而信息利用的不充分、原始数据的噪声及各个传感器间的错位(如时间戳不同步),这些因素都导致融合性能一直受限。本文全面调研了现有多模态自动驾驶感知算法,传感器包括LiDAR和相机,聚焦于目标检测和语义分割,分析超过50篇文献。同传统融合算法分类方法不同,本文从融合阶段的不同将该领域分类两大类、四小类。此外,本文分析了当前领域存在的问题,对未来的研究方向提供参考。
2 为什么需要多模态?
这是因为单模态的感知算法存在固有的缺陷。举个例子,一般激光雷达的架设位置是高于相机的,在复杂的现实驾驶场景中,物体在前视摄像头中可能被遮挡,此时利用激光雷达就有可能捕获缺失的目标。但是由于机械结构的限制,LiDAR在不同的距离有不同的分辨率,而且容易受到极端恶劣天气的影响,如暴雨等。虽然两种传感器单独使用都可以做的很出色,但从未来的角度出发,LiDAR和相机的信息互补将会使得自动驾驶在感知层面上更安全。
近期,自动驾驶多模态感知算法取得了巨大进步。这些进步包括跨模态的特征表示、更可靠的模态传感器、更复杂、更稳定的多模态融合算法和技术。然而,只有少数综述[15, 81]专注于多模态融合的方法论本身,大多数文献都按照传统分类规则进行分类,即前融合、深度(特征)融合和后融合三大类,并主要关注算法中特征融合的阶段,无论是数据级、特征级还是提议级。这种分类规则存在两个问题:首先,没有明确定义每个级别的特征表示;其次,它从对称的角度处理激光雷达和相机这两个分支,进而模糊了LiDAR分支中提级级特征融合和相机分支中数据级特征融合的情况。总结来说,传统分类法虽然直观,但已经不适用于当前多模态融合算法的发展,一定程度上阻碍了研究人员从系统的角度进行研究和分析
3 任务和公开比赛
常见的感知任务包括目标检测、语义分割、深度补全和预测等。本文重点关注检测和分割,如障碍物、交通信号灯、交通标志的检测和车道线、freespace的分割等。自动驾驶感知任务如下图所示:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
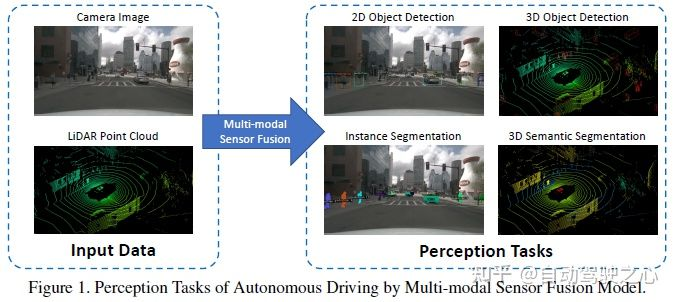
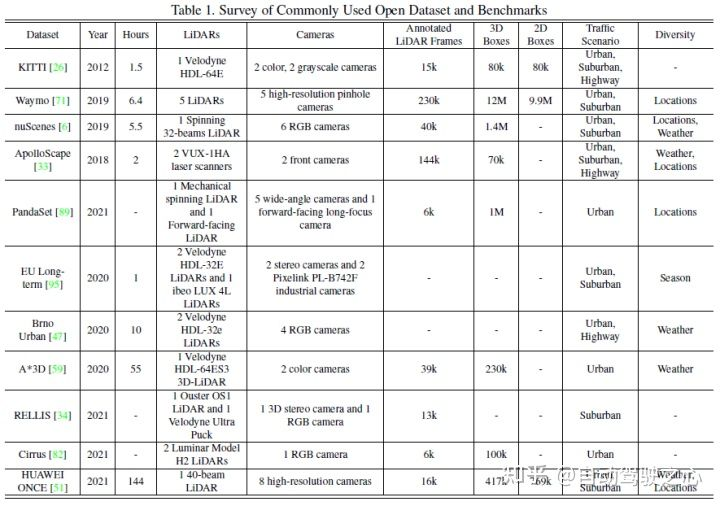
常见的公开数据集主要包括KITTI、Waymo和nuScenes,下图总结了自动驾驶感知相关的数据集及其特点
4 融合方法
多模态融合离不开数据表达形式,图像分支的数据表示较简单,一般均指RGB格式或灰度图,但激光雷达分支对数据格式的依赖度较高,不同的数据格式衍生出完全不同的下游模型设计,总结来说包含三个大方向:基于点、基于体素和基于二维映射的点云表示。
传统分类方法将多模态融合分为以下三种:
- 前融合(数据级融合)指通过空间对齐直接融合不同模态的原始传感器数据。
- 深度融合(特征级融合)指通过级联或者元素相乘在特征空间中融合跨模态数据。
- 后融合(目标级融合)指将各模态模型的预测结果进行融合,做出最终决策。
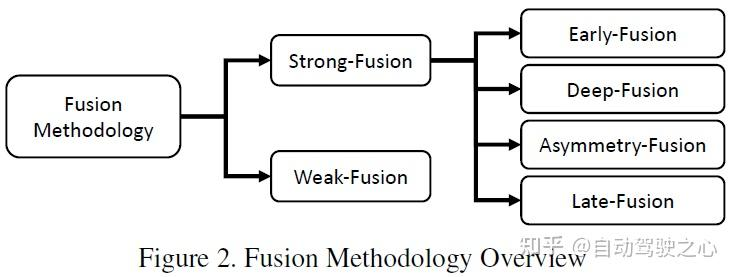
文章使用下图的分类方式,总体分为强融合和若融合,强融合又可细分为前融合、深度融合、不对称融合和后融合
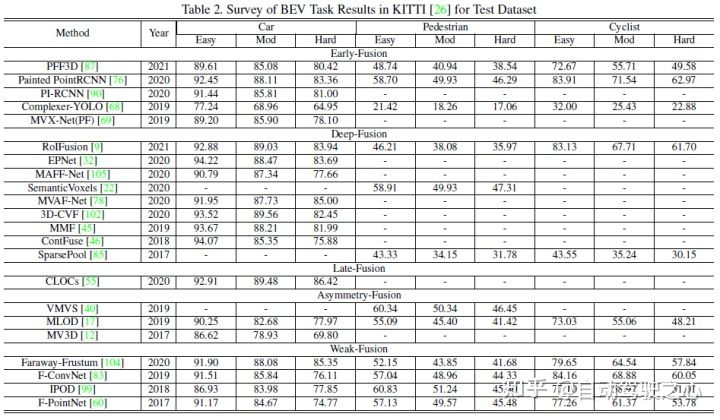
本文使用KITTI的3D检测任务和BEV检测任务横向对比各个多模态融合算法的性能,下图是BEV检测测试集的结果:
以下是3D检测测试集的结果示例图:
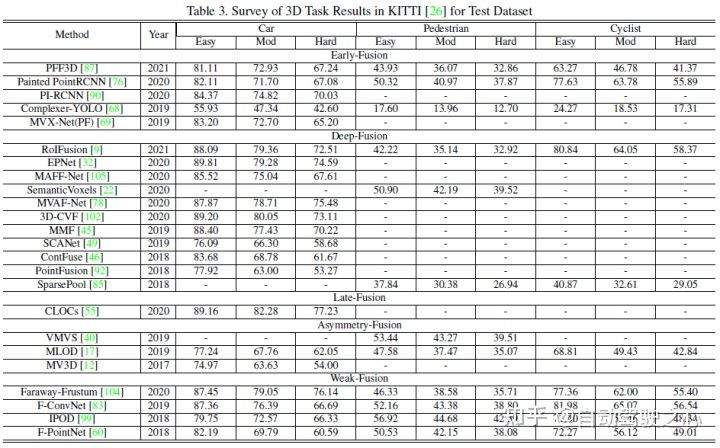
5 强融合
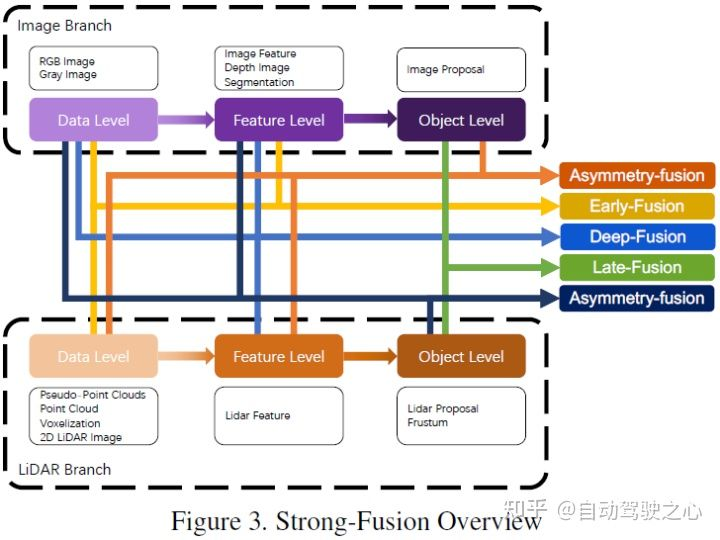
根据激光雷达和相机数据表示的不同组合阶段,本文将强融合细分为:前融合、深度融合、不对称融合和后融合。如上图所示可以看出,强融合的每个子模块都高度依赖于激光雷达点云,而不是相机数据。
前融合
与传统的数据级融合定义不同,后者是一种在原始数据级别通过空间对齐和投影直接融合每种模态数据的方法,早期融合在数据级别融合LiDAR 数据和数据级别的相机数据或特征级。早期融合的一个例子可以是图4中的模型。 重写后的内容: 与传统的数据级融合定义不同,后者是一种通过在原始数据级别上进行空间对齐和投影,直接融合每种模态数据的方法。早期融合是指在数据级别上融合LiDAR数据和相机数据或特征级别的数据。图4中的模型是早期融合的一个例子
与传统分类方法定义的前融合不同,本文定义的前融合是指在原始数据级别通过空间对齐和投影直接融合各个模态数据的方法,前融合在数据级指的是融合激光雷达数据,在数据级或特征级融合图像数据,示意图如下:
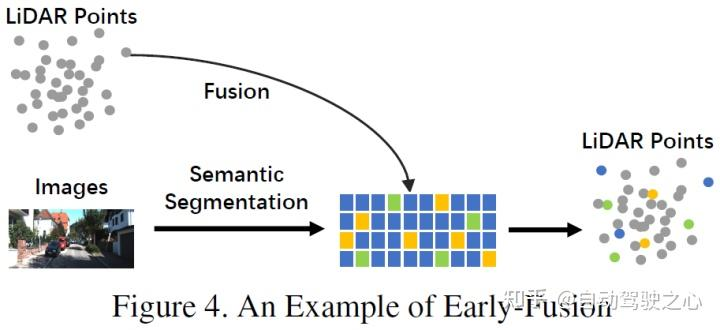
在LiDAR分支中,点云有多种表达方式,比如反射图、体素化张量、前视图/距离视图/BEV视图以及伪点云等。尽管这些数据在不同主干网络中具有不同的内在特征,但除了伪点云之外[79],大部分数据都是通过一定的规则处理生成的。此外,与特征空间嵌入相比,LiDAR的这些数据都具有很强的可解释性,可以直接进行可视化展示
 Glarity
Glarity
Glarity是一款免费开源的AI浏览器扩展,提供YouTube视频总结、网页摘要、写作工具等功能,支持免费的镜像翻译,电子邮件写作辅助,AI问答等功能。
 131
查看详情
131
查看详情

在图像分支中,严格意义上的数据级定义是指RGB或灰度图像,但是这个定义缺乏普适性和合理性。因此,本文对前融合阶段的图像数据的数据级定义进行了扩展,包括数据级和特征级数据。值得一提的是,本文将语义分割的预测结果也作为前融合的一种(图像特征级),一方面是因为它有助于3D目标检测,另一方面是因为语义分割的“目标级”特征与整个任务的最终目标级提议是不同的
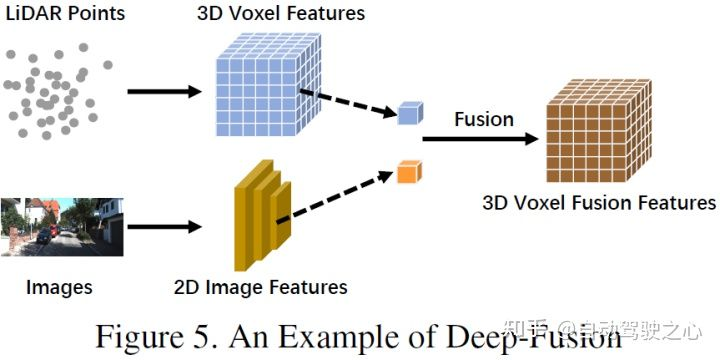
深度融合
深度融合,也称特征级融合,是指在激光雷达分支的特征级融合多模态数据,但在图像分支的数据集和特征级进行融合。例如一些方法使用特征提举起分别获取LiDAR点云和图像的嵌入表示,并通过一系列下游模块融合两种模态的特征。然而,与其他强融合不同的是,深度融合有时会以级联方式融合特征,这两者都利用了原始和高级语义信息。示意图如下:
后融合
后融合,也可以称为目标级融合,是指对多个模态的预测结果(或提案)进行融合。例如,一些后融合方法利用LiDAR点云和图像的输出进行融合[55]。两个分支的提案数据格式应与最终结果一致,但质量、数量和精度可能存在差异。后融合可以被看作是一种多模态信息优化最终提案的集成方法,示意图如下所示:
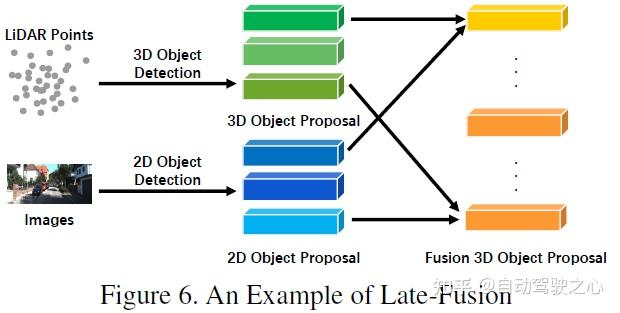
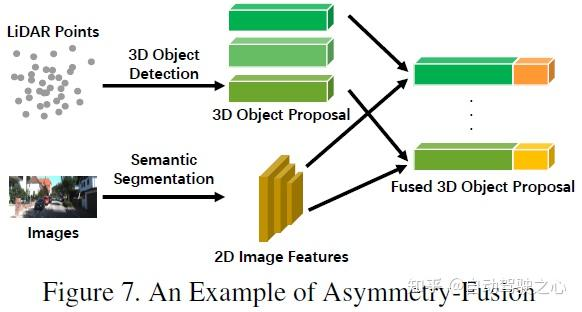
不对称融合
强融合的最后一种是不对称融合,指的是融合一个分支的目标级信息和其他分支的数据级或特征级信息。上述三种融合方法将多模态的各个分支平等对待,不对称融合则强调至少有一个分支占据主导地位,其他分支则提供辅助信息预测最终结果。下图是不对称融合的示意图,在proposal阶段,不对称融合只有一个分支的proposal,而后融合则是所有分支的proposal。
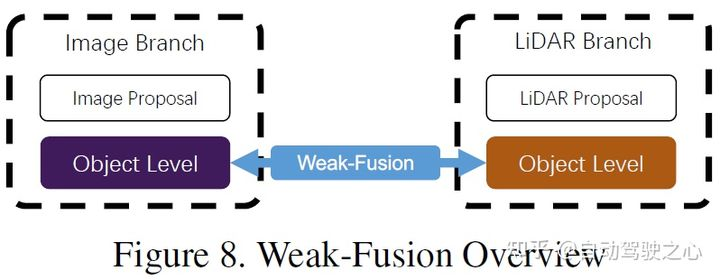
6 弱融合
与强融合的区别在于,弱融合方法不直接从多模态分支中融合数据、特征或者目标,而是以其他形式处理数据。下图展示了弱融合算法的基本框架。基于弱融合的方法通常使用基于一定规则的方法来利用一种模态的数据作为监督信号,以指导另一种模态的交互。例如,图像分支中来自CNN的2D proposal可能会导致原始LiDAR点云中出现截断,弱融合直接将原始LiDAR 点云输入到 LiDAR 主干中以输出最终的proposal。
7 其他方式融合
还有一些工作不属于上述任何一种范式,因为它们在模型设计的框架中使用了多种融合方式,例如[39]结合了深度融合和后融合,[77]则结合了前融合。这些方法不是融合算法设计的主流方式,本文统一归为其他融合方式。
8 多模态融合的机遇
近年来,用于自动驾驶感知任务的多模态融合方法取得了快速进展,从更高级的特征表示到更复杂的深度学习模型。然而,还有一些悬而未决的问题有待解决,本文总结了如下几个未来可能的改进方向 。
更先进的融合方法
当前的融合模型存在错位和信息丢失的问题[13,67,98]。此外,平融合(flat fusion)操作也阻碍了感知任务性能的进一步提高。总结如下:
- 错位和信息丢失:相机和LiDAR的内外在差异很大,两种模态的数据需要进行坐标对齐。传统的前融合和深度融合方法利用标定信息将所有LiDAR点直接投影到相机坐标系,反之亦然。然而由于架设位置、传感器噪声,这种逐像素的对齐是不够准确的。因此,一些工作利用周围信息进行补充以获取更好的性能。此外,在输入和特征空间的转换过程中,还存在一些其他信息的丢失。通常,降维操作的投影不可避免地会导致大量信息丢失,如将3D LiDAR点云映射为2D BEV图像中则损失了高度信息。因此,可以考虑将多模态数据映射到另一种专为融合设计的高维空间,进而有效的利用原始数据,减少信息损失。
- 更合理的融合操作:当前许多方法使用级联或者元素相乘的方式进行融合。这些简单的操作可能无法融合分布差异较大的数据,因此难以拟合两个模态间的语义红狗。一些工作试图使用更复杂的级联结构来融合数据并提高性能。在未来的研究中,双线性映射等机制可以融合具有不同特点的特征,也是可以考虑的方向。
多源信息利用
前视单帧图像是自动驾驶感知任务的典型场景。然而,大多数框架只能利用有限的信息,并未详细设计辅助任务来促进驾驶场景的理解。总结如下:
- 采用更多的潜在信息:现有方法缺乏对个维度和来源的信息的有效利用。大多数都将精力放在前视图中的单帧多
 模态数据上。这就导致其他有意义的数据并未被充分利用,例如语义、空间和场景上下文信息。一些工作尝试使用语义分割结果辅助任务,而其他模型则有可能利用CNN主干的中间层特征。在自动驾驶场景中,许多具有显式语义信息的下游任务可能会极大的提高目标检测性能,例如车道线、交通灯和交通标志的检测。未来的研究可以结合下游任务,共同构建一个完整的城市场景的语义理解框架,来提升感知性能。此外,[63]结合了帧间信息提升性能。时间序列信息包含序列化的监控信号,与单帧方法相比,它可以提供更稳定的结果。因此,未来的工作可以考虑更深入地利用时间、上下文和空间信息来实现性能突破。
模态数据上。这就导致其他有意义的数据并未被充分利用,例如语义、空间和场景上下文信息。一些工作尝试使用语义分割结果辅助任务,而其他模型则有可能利用CNN主干的中间层特征。在自动驾驶场景中,许多具有显式语义信息的下游任务可能会极大的提高目标检测性能,例如车道线、交通灯和交通标志的检测。未来的研究可以结合下游任务,共同构建一个完整的城市场景的语义理解框架,来提升感知性能。此外,[63]结合了帧间信息提升性能。时间序列信息包含序列化的监控信号,与单帧方法相比,它可以提供更稳定的结果。因此,未来的工作可以考虑更深入地利用时间、上下文和空间信息来实现性能突破。 - 自监督表征学习:互相监督的信号自然存在于从同一个真实世界场景但不同角度采样的跨模态数据中。然而,由于缺乏对数据的深入理解,目前的方法还无法挖掘各个模态间的相互关系。未来的研究可以集中在如何利用多模态数据进行自监督学习,包括预训练、微调或者对比学习。通过这些最先进的机制,融合算法将加深模型对数据更深层次的理解,同时取得更好的性能。
 模态数据上。这就导致其他有意义的数据并未被充分利用,例如语义、空间和场景上下文信息。一些工作尝试使用语义分割结果辅助任务,而其他模型则有可能利用CNN主干的中间层特征。在自动驾驶场景中,许多具有显式语义信息的下游任务可能会极大的提高目标检测性能,例如车道线、交通灯和交通标志的检测。未来的研究可以结合下游任务,共同构建一个完整的城市场景的语义理解框架,来提升感知性能。此外,[63]结合了帧间信息提升性能。时间序列信息包含序列化的监控信号,与单帧方法相比,它可以提供更稳定的结果。因此,未来的工作可以考虑更深入地利用时间、上下文和空间信息来实现性能突破。
模态数据上。这就导致其他有意义的数据并未被充分利用,例如语义、空间和场景上下文信息。一些工作尝试使用语义分割结果辅助任务,而其他模型则有可能利用CNN主干的中间层特征。在自动驾驶场景中,许多具有显式语义信息的下游任务可能会极大的提高目标检测性能,例如车道线、交通灯和交通标志的检测。未来的研究可以结合下游任务,共同构建一个完整的城市场景的语义理解框架,来提升感知性能。此外,[63]结合了帧间信息提升性能。时间序列信息包含序列化的监控信号,与单帧方法相比,它可以提供更稳定的结果。因此,未来的工作可以考虑更深入地利用时间、上下文和空间信息来实现性能突破。传感器固有问题
现实世界的场景和传感器高度会影响域偏差和分辨率。这些不足会妨碍自动驾驶深度学习模型的大规模训练和实时操作
- 域偏差:在自动驾驶感知场景中,不同传感器提取的原始数据伴随着严重的领域相关特征。不同的摄像头有不同的光学特性,而LiDAR可能会从机械结构到固态结构而有所不同。更重要的是,数据本身会存在域偏差,例如天气、季节或地理位置,即使它是由相同的传感器捕获的。这就导致检测模型的泛化性受到影响,无法有效适应新场景。这类缺陷阻碍了大规模数据集的收集和原始训练数据的复用性。因此,未来可以聚焦于寻找一种消除域偏差并自适应集成不同数据源的方法。
- 分辨率冲突:不同的传感器通常有不同的分辨率。例如,LiDAR的空间密度明显低于图像的空间密度。无论采用哪种投影方式,都会因为找不到对应关系而导致信息损失。这可能会导致模型被一种特定模态的数据所主导,无论是特征向量的分辨率不同还是原始信息的不平衡。因此,未来的工作可以探索一种与不同空间分辨率传感器兼容的新数据表示系统。
9参考
[1] https://zhuanlan.zhihu.com/p/470588787
[2] Multi-modal Sensor Fusion for Auto Driving Perception: A Survey

原文链接:https://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
以上就是深入探讨多模态融合感知算法在自动驾驶中的应用的详细内容,更多请关注其它相关文章!
# 两种
# 城市网站建设文案怎么写
# 四平seo网站优化
# 营销套餐推广活动
# 京东商品关键词排名工具
# 海南一般的网站推广是什么
# 无为网站关键词优化
# 宁夏全网营销推广品牌
# 静海区全网营销推广渠道
# 餐厅前期推广营销策略
# 南宁个人网站优化电话
# 算法
# 是一种
# 原始数据
# 的是
# 未来
# 不对称
# 是指
# 模态
# 多模
# 关键词
# 自动驾驶
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
js怎么设置typescript
什么叫typescript
美食音乐每日推荐怎么写
苹果ipad爱奇艺怎么投屏到电视
学typescript要求什么
固态硬盘如何打开软件
市盈率估值1stdv是什么意思
苹果16颜色有哪些
通配符的用法
j*a对数组怎么使用
如何查找固态硬盘
市盈率ttm是什么意思
如何编写一个linux命令
买的5g手机但是没有5g网络怎么办
如何判断固态硬盘
如何以命令符运行程序
如何ping测试命令
三星固态硬盘如何保修
如何在一串数字前面去掉四位数的命令
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
春运抢票要用抢票软件吗
划水是什么意思
苹果16有哪些改装模式
固态硬盘如何接主机
如何检测固态硬盘温度
driver是什么意思
单片机for循环怎么用
固态硬盘 如何分区
如何用固态硬盘做缓存
电动车充电器上的power是什么意思
solidworks打开igs文件看不见要怎么办解决方法
苹果16都有哪些亮点
如何查看电脑的固态硬盘
angluar如何命令删除dist
对应市盈率是30X是什么意思
光刻机的分类及其优缺点
科技型企业成长"十步法"
智能锁type-c接口是什么
交管12123协议头是什么
三星固态硬盘如何安装
如何让固态硬盘坏掉
如何更新固态硬盘固件
ao3镜像网站哪个好
openwrt有什么用
征信不好如何恢复信誉度 征信不好恢复信誉度的方法
计数器上power是什么意思
如何安装台式机固态硬盘
typescript掌握哪些可以做项目
linux如何安装yum命令
华为使用nfc功能是什么意思
